Addition
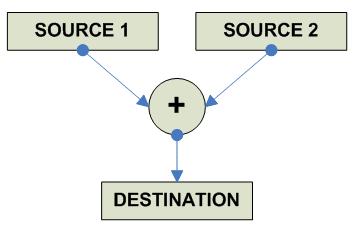
Сложение Addition
destination = source1 + source2; |
add ax,bx into ; Trap if overflow flag set |
add eax,ebx jo label ; Conditionalm Jump if Overflow |

destination = source1 + source2 + CF; |
; R1:R2 = R3:R4 + R5:R6 ; used R7 add r2,r4,r6 sltu r7,r2,r4 add r1,r3,r5 add r1,r1,r7 |
// Addition: R1:R2 = R3:R4 + R5:R6 add r2 = r4,r6 ;; cmp.ltu p1,p2 = r2,r4 ;; (p1) add r1 = r3,r5,1 (p2) add r1 = r2,r5 |

destination = source1 + source2 * scale |
lea eax,[ebx + ecx * 8 + 1234h] |
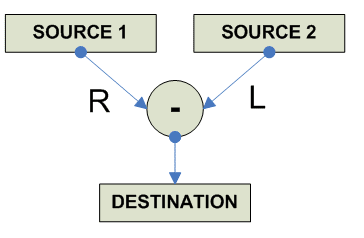
destination = source1 - source2 |
PowerPC поддерживают интересную операцию subfic: |

destination = source1 - source2 - CF |

destination = source1 - source2 * scale |
destination = source1 (unsigned *) source2 |
MULU Multiply Unsigned XX * XX -> XXXX |
MULL Multiply Low (Signed/Unsigned) XX * XX -> LOW(XXXX) = XX |
MULHU Multiply High Unsigned XX * XX -> HIGH(XXXX) = XX |
Как правило процессоры имеют либо инструкцию типа MULU (результат часто может записываться только в определенные регистры (пример: x86: EDX:EAX, MIPS: HI:LO)), либо набор MULL и пару MULH - одну для знакового, другое для беззнакового умножения. При полном умножении MULU или при MULHU переполнение не может возникнуть, поэтому OF=0 ------------------------------------------------------------------------------ o Unsigned Integer Multiply x86 MUL 8 AccR ( 8x8 -> 16) 16 AccR (16x16 -> 32) 32 AccR (32x32 -> 64) ---------------------------------------- Alpha UMULH 64 RRR RRI (64x64 -> 128 (high)) MULQ 64 RRR RRI (64x64 -> 128 (low))) ---------------------------------------- PPC MULHWU 32 RRR (32x32 -> 64 (high)) MULL 32 RRR (32x32 -> 64 (low)) MULHDU 64 RRR (64x64 -> 128 (high)) MULLD 64 RRR (64x64 -> 128 (low)) ---------------------------------------- MIPS MULTU 32 AccR (32x32 -> 64) (HI,LO) DMULTU 64 AccR (64x64 -> 128) (HI,LO) ---------------------------------------- SPARC UMUL 32 RRR RRI MULX 64 RRR V9 (Generic 64bit Mul) ---------------------------------------- 68K MULU 16 RR (D-regs) (16x16 -> 32) 32 RR (32x32 -> 32) ?? ---------------------------------------- z80 (*) Complex sequence ---------------------------------------- HPPA ??? ---------------------------------------- VAX-11 ??? MULB2 8 RR MULB3 8 RRR MULW2 16 RR MULW3 16 RRR MULL2 32 RR MULL3 32 RRR ----------------------------------------- MCS51 MUL 8 AB (BA <- A x B) ----------------------------------------- ARM UMULLcc 32 RRRR (32:32 <- 32 * 32) ----------------------------------------- SH4 MULU.W RR (16x16 -> 32) DMULU.L RR (32x32 -> 64)
HP-PA Multiply: #ifdef L_multiply #define op0 %r26 #define op1 %r25 #define res %r29 #define ret %r31 #define tmp %r1 SPACE GSYM($$mulU) GSYM($$mulI) .proc .callinfo frame=0,no_calls .entry addi,tr 0,%r0,res ; clear out res, skip next insn LSYM(loop) zdep op1,26,27,op1 ; shift up op1 by 5 LSYM(lo) zdep op0,30,5,tmp ; extract next 5 bits and shift up blr tmp,%r0 extru op0,26,27,op0 ; shift down op0 by 5 LSYM(0) comib,<> 0,op0,LREF(lo) zdep op1,26,27,op1 ; shift up op1 by 5 bv %r0(ret) nop LSYM(1) b LREF(loop) addl op1,res,res nop nop LSYM(2) b LREF(loop) sh1addl op1,res,res nop nop LSYM(3) sh1addl op1,op1,tmp ; 3x b LREF(loop) addl tmp,res,res nop LSYM(4) b LREF(loop) sh2addl op1,res,res nop nop LSYM(5) sh2addl op1,op1,tmp ; 5x b LREF(loop) addl tmp,res,res nop LSYM(6) sh1addl op1,op1,tmp ; 3x b LREF(loop) sh1addl tmp,res,res nop LSYM(7) zdep op1,28,29,tmp ; 8x sub tmp,op1,tmp ; 7x b LREF(loop) addl tmp,res,res LSYM(8) b LREF(loop) sh3addl op1,res,res nop nop LSYM(9) sh3addl op1,op1,tmp ; 9x b LREF(loop) addl tmp,res,res nop LSYM(10) sh2addl op1,op1,tmp ; 5x b LREF(loop) sh1addl tmp,res,res nop LSYM(11) sh2addl op1,op1,tmp ; 5x sh1addl tmp,op1,tmp ; 11x b LREF(loop) addl tmp,res,res LSYM(12) sh1addl op1,op1,tmp ; 3x b LREF(loop) sh2addl tmp,res,res nop LSYM(13) sh1addl op1,op1,tmp ; 3x sh2addl tmp,op1,tmp ; 13x b LREF(loop) addl tmp,res,res LSYM(14) zdep op1,28,29,tmp ; 8x sub tmp,op1,tmp ; 7x b LREF(loop) sh1addl tmp,res,res LSYM(15) zdep op1,27,28,tmp ; 16x sub tmp,op1,tmp ; 15x b LREF(loop) addl tmp,res,res LSYM(16) zdep op1,27,28,tmp ; 16x b LREF(loop) addl tmp,res,res nop LSYM(17) zdep op1,27,28,tmp ; 16x addl tmp,op1,tmp ; 17x b LREF(loop) addl tmp,res,res LSYM(18) sh3addl op1,op1,tmp ; 9x b LREF(loop) sh1addl tmp,res,res nop LSYM(19) sh3addl op1,op1,tmp ; 9x sh1addl tmp,op1,tmp ; 19x b LREF(loop) addl tmp,res,res LSYM(20) sh2addl op1,op1,tmp ; 5x b LREF(loop) sh2addl tmp,res,res nop LSYM(21) sh2addl op1,op1,tmp ; 5x sh2addl tmp,op1,tmp ; 21x b LREF(loop) addl tmp,res,res LSYM(22) sh2addl op1,op1,tmp ; 5x sh1addl tmp,op1,tmp ; 11x b LREF(loop) sh1addl tmp,res,res LSYM(23) sh1addl op1,op1,tmp ; 3x sh3addl tmp,res,res ; += 8x3 b LREF(loop) sub res,op1,res ; -= x LSYM(24) sh1addl op1,op1,tmp ; 3x b LREF(loop) sh3addl tmp,res,res ; += 8x3 nop LSYM(25) sh2addl op1,op1,tmp ; 5x sh2addl tmp,tmp,tmp ; 25x b LREF(loop) addl tmp,res,res LSYM(26) sh1addl op1,op1,tmp ; 3x sh2addl tmp,op1,tmp ; 13x b LREF(loop) sh1addl tmp,res,res ; += 2x13 LSYM(27) sh1addl op1,op1,tmp ; 3x sh3addl tmp,tmp,tmp ; 27x b LREF(loop) addl tmp,res,res LSYM(28) zdep op1,28,29,tmp ; 8x sub tmp,op1,tmp ; 7x b LREF(loop) sh2addl tmp,res,res ; += 4x7 LSYM(29) sh1addl op1,op1,tmp ; 3x sub res,tmp,res ; -= 3x b LREF(foo) zdep op1,26,27,tmp ; 32x LSYM(30) zdep op1,27,28,tmp ; 16x sub tmp,op1,tmp ; 15x b LREF(loop) sh1addl tmp,res,res ; += 2x15 LSYM(31) zdep op1,26,27,tmp ; 32x sub tmp,op1,tmp ; 31x LSYM(foo) b LREF(loop) addl tmp,res,res .exit .procend #endif |
destination = source1 (signed *) source2 |
MULS Multiply Signed XX * XX -> XXXX |
MULHS Multiply High Unsigned XX * XX -> HIGH(XXXX) = XX |
destination = source1 (unsigned /) source2 |



# 64-bit signed divd RT,RA,RB # RT = quotient mulld RT,RT,RB # RT = quotient * divisor subf RT,RT,RA # RT = remainder |
HP-PA Divide
#ifdef L_divU
#define dividend %r26
#define divisor %r25
#define tmp %r1
#define quotient %r29
#define ret %r31
SPACE
GSYM($$divU)
.proc
.callinfo frame=0,no_calls
.entry
comb,< divisor,0,LREF(largedivisor)
sub %r0,divisor,%r1 ; clear cy as side-effect
ds %r0,%r1,%r0
addc dividend,dividend,dividend
ds %r0,divisor,%r1
addc dividend,dividend,dividend
ds %r1,divisor,%r1
addc dividend,dividend,dividend
ds %r1,divisor,%r1
addc dividend,dividend,dividend
ds %r1,divisor,%r1
addc dividend,dividend,dividend
ds %r1,divisor,%r1
addc dividend,dividend,dividend
ds %r1,divisor,%r1
addc dividend,dividend,dividend
ds %r1,divisor,%r1
addc dividend,dividend,dividend
ds %r1,divisor,%r1
addc dividend,dividend,dividend
ds %r1,divisor,%r1
addc dividend,dividend,dividend
ds %r1,divisor,%r1
addc dividend,dividend,dividend
ds %r1,divisor,%r1
addc dividend,dividend,dividend
ds %r1,divisor,%r1
addc dividend,dividend,dividend
ds %r1,divisor,%r1
addc dividend,dividend,dividend
ds %r1,divisor,%r1
addc dividend,dividend,dividend
ds %r1,divisor,%r1
addc dividend,dividend,dividend
ds %r1,divisor,%r1
addc dividend,dividend,dividend
ds %r1,divisor,%r1
addc dividend,dividend,dividend
ds %r1,divisor,%r1
addc dividend,dividend,dividend
ds %r1,divisor,%r1
addc dividend,dividend,dividend
ds %r1,divisor,%r1
addc dividend,dividend,dividend
ds %r1,divisor,%r1
addc dividend,dividend,dividend
ds %r1,divisor,%r1
addc dividend,dividend,dividend
ds %r1,divisor,%r1
addc dividend,dividend,dividend
ds %r1,divisor,%r1
addc dividend,dividend,dividend
ds %r1,divisor,%r1
addc dividend,dividend,dividend
ds %r1,divisor,%r1
addc dividend,dividend,dividend
ds %r1,divisor,%r1
addc dividend,dividend,dividend
ds %r1,divisor,%r1
addc dividend,dividend,dividend
ds %r1,divisor,%r1
addc dividend,dividend,dividend
ds %r1,divisor,%r1
addc dividend,dividend,dividend
ds %r1,divisor,%r1
addc dividend,dividend,quotient
ds %r1,divisor,%r1
bv %r0(ret)
addc quotient,quotient,quotient
LSYM(largedivisor)
comclr,<< dividend,divisor,quotient
ldi 1,quotient
bv,n %r0(ret)
.exit
.procend
#endif
|
destination = source1 (signed /) source2 |




destination = destination + 1 |
inc %r5 => add %r5,1,%r5 inccc %r5 => addcc %r5,1,%r5 |

destination = destination - 1 |
dec %r5 => sub %r5,1,%r5 deccc %r5 => subcc %r5,1,%r5 |

destination = - source |
neg %r5 => sub %g0,%r5,%r5 neg %r5,%r6 => sub %g0,%r5,%r6 |







