50.7.1. МИКРООПЕРАЦИИ И КЭШИРОВАНИЕ КОДА
THIS SECTION IS UNDER CONSTRUCTION
Кэш инструкций
Обычные RISC процессоры все хорошо - инструкции фиксированной длинны и
выполняются как правило за 1 такт - все хорошо.
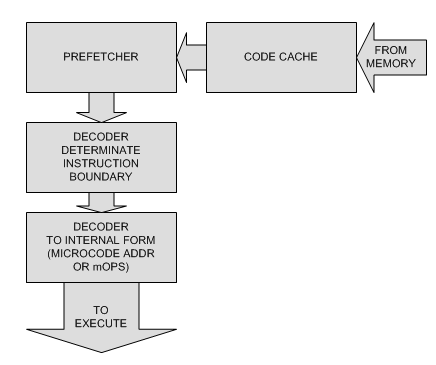
В случае же CISC процессоров у нас сложная система комманд переменной длинны.
Поэтому с целью минимизации времени работы code cache стал опускаться по
конвееру ближе к выполняемым устройствам.
Кэш полудекодированных инструкций
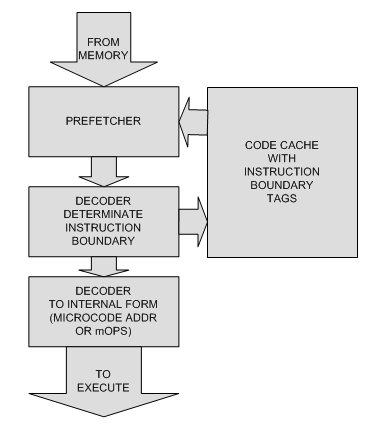
Первая стадия была - сохранение в cache информации о границах инструкций
Это позволило пробросить одну стадию конвеера.
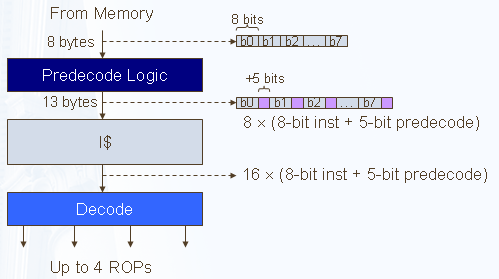
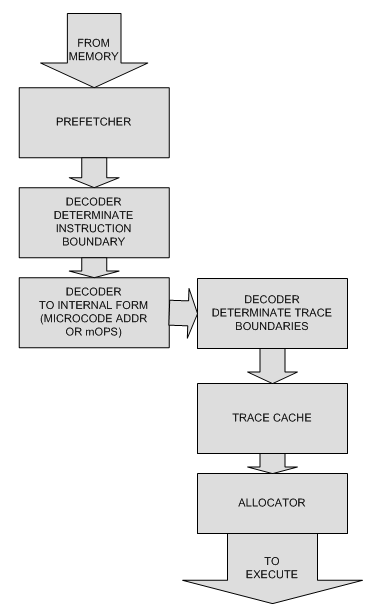
Кэш микроопераций
Затем пришел out-of-order execution. Процессоры стали преобразовывать команды
во инструкции для внутренного ядра (mOPS).
Как правило декодоры были нескольких типов:
для простых операций однозначно преобразуемых в микрооперации (типа ADD)
и для сложных инструкций генерирующих последовательность микроопраций.
Понятно что блок для сложных инструкций гораздо сложнее, поэтому их меньше.
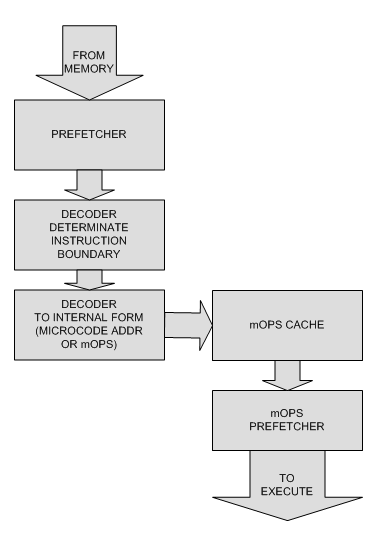
Пример блока декодирования для Intel Core:
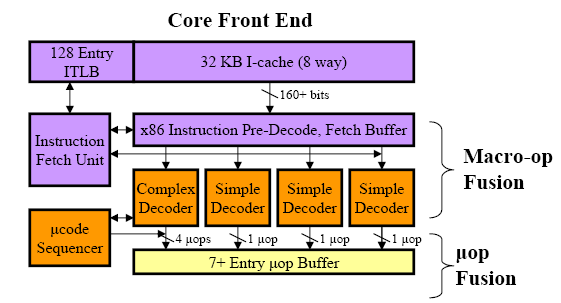
Соответственно cache инструкций сместился еще дальше по конвееру и стал хранить
уже mOPS.
Trace кэш
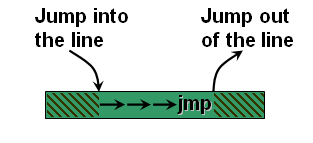
Дальнейшее развитие привело от mOPS-cache к Trace-cache, который уже содержал
не микрооперации, а последовательности микроопераций которые не прерывались
входящими/исходящими переходами (traces), и будучи запущенными выполнялись
полностью, что повышало производительность.

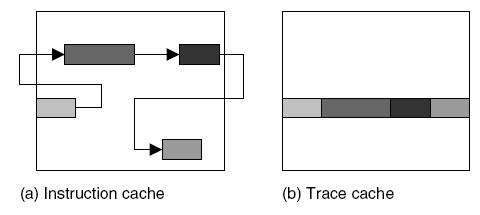
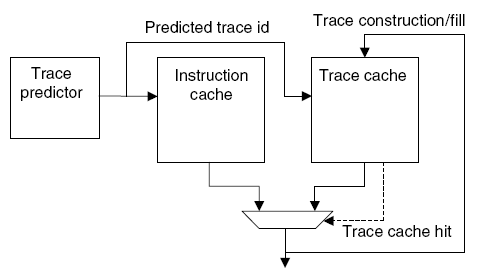
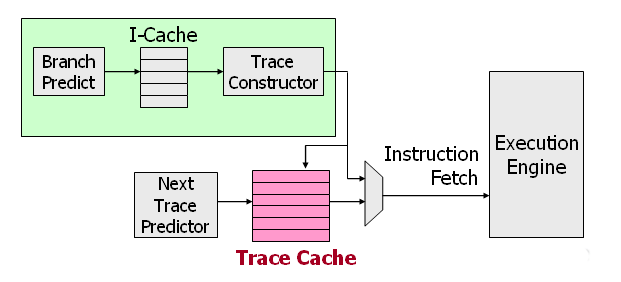
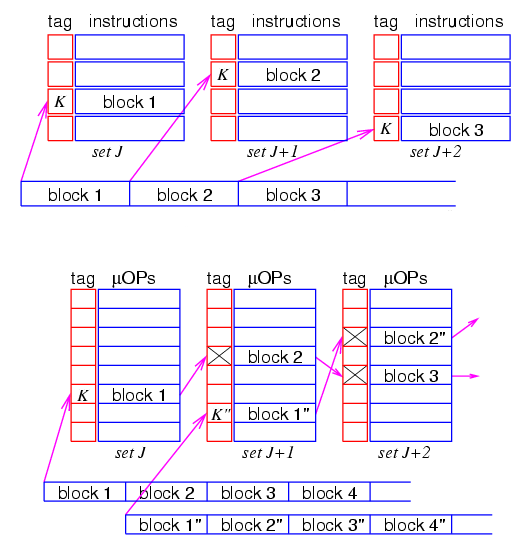
Организация T-cache в сравнении с I-cache.
Старшие биты адресса инструкции это Tag, младшие Set.
(т.е. N-way associative)
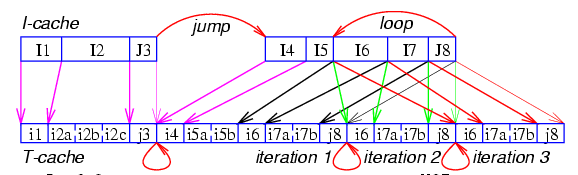
Кроме того trace-cache может использоватся для развертки коротких циклов:
VLIW mOPS
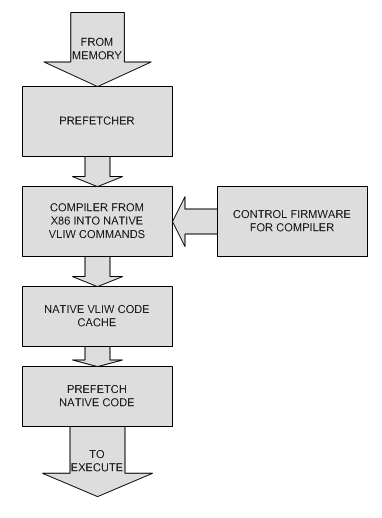
Другой подход был использован в процессорах Transmeta Crusoe. Там использовался
встроеенный в процессор Firmware компилятор, который преобразовывал входящие x86
комманды в native VLIW комманды процессора. Естественно code cache хранил
именно эти комманды.
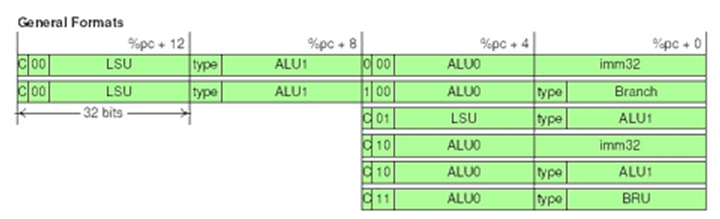
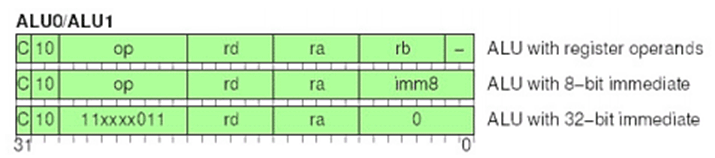
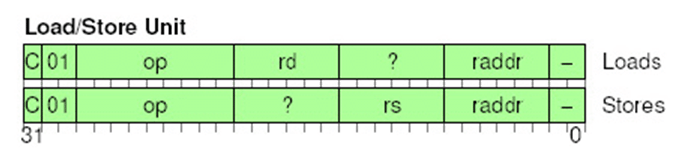
Форматы VLIW комманд Crusoe:
Index Prev Next