Spin-семантика
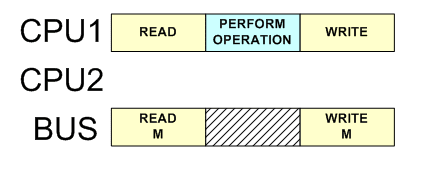
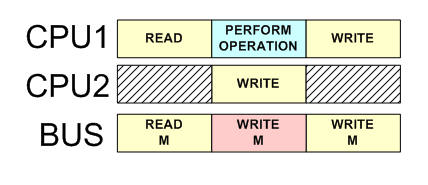
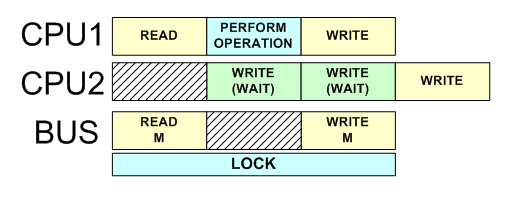
Locked операции на шине
Mutex
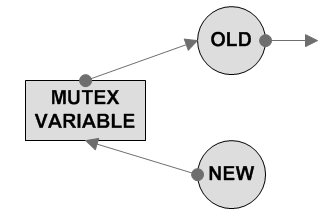
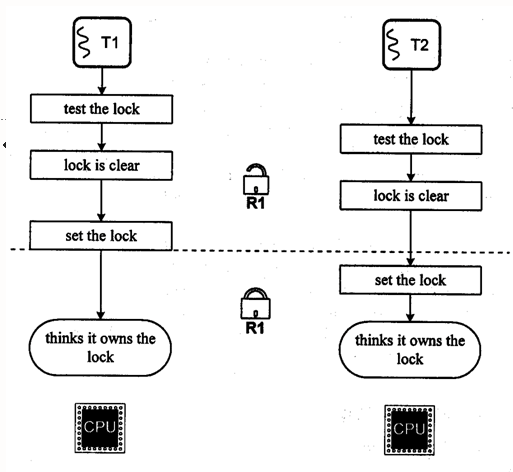
Операция для захваты mutexа должна быть атомарной, иначе начинаются гонки:
Реализуется как правило нижнеуровневыми командами вида: Для x86. LOCK XCHG LOCK битовые операции (BTS, BTC) XCHG dest, src dest < --- > src BTS dest, bit_number CF = BIT(dest, bit_number) BIT(dest, bit_number) = 1 BTC dest, bit_number CF = BIT(dest, bit_number) BIT(dest, bit_number) = 0 Пример реализации: --------------------------------------------------------------------- mutex_init(&mutex, MUTEX_UNLOCKED) mov [mutex], 0 mutex_init(&mutex, MUTEX_LOCKED) mov [mutex], 1 --------------------------------------------------------------------- bool mutex_trylock(&mutex) mov eax, 1 lock xchg [mutex],eax or eax,eax mov eax, FALSE mov ebx, TRUE cmovz eax, ebx ret --------------------------------------------------------------------- mutex_unlock(&mutex) lock mov [mutex],0 --------------------------------------------------------------------- пример реализации на битовых операциях (используем бит # N) --------------------------------------------------------------------- bool mutex_trylock(&mutex) lock bts [mutex], N mov eax, FALSE mov ebx, TRUE cmovc eax, ebx ret --------------------------------------------------------------------- mutex_unlock(&mutex) lock btc [mutex], N ---------------------------------------------------------------------
Spin lock
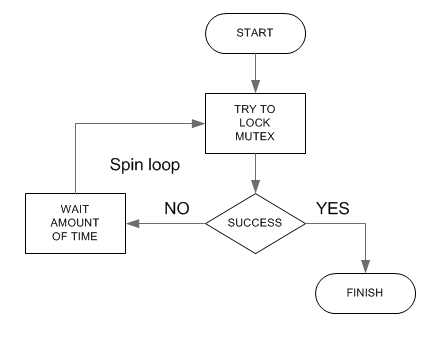
Пример реализации: --------------------------------------------------------------------- spinmutex_lock(&mutex) ?spin_loop: mov eax,1 lock xchg [mutex],eax or eax,eax jz ?lock_success ;; wait jmp ?spin_loop ?lock_success: ret --------------------------------------------------------------------- Основная проблема spin-lock, это то что процессор сидящий в spin-loop переодически пытается сделать лоченную операцию к шине, что приводит к потере быстродействия системы, так как лоченные операции выполняются на порядок медленнее чем обычные. Есть команда которая ждет определенное фиксированное количество времени PAUSE Поэтому в современные микропроцессоры стали вводить команды оптимизирующие spin-locks. Например современные процессоры Intel имеют команды MONITOR и MWAIT Команда MONITOR указывает адресс который будет мониториться (в EAX), команда MWAIT осуществляет ожидание, Если происходит обращение к указанному адрессу (понятное дело из другого ядра или процессора или bus-master оборудования), то команда MWAIT заканчивает свое выполнение и управление передается следующей команды (в зависимости от параметров передаваемых в регистрах MWAIT может также прерываться а может не прерываться по прерываниям, но по NMI, SMI будет все равно прерываться). Вот так будет выглядеть spin-lock используя эти инструкции. --------------------------------------------------------------------- spinmutex_lock(&mutex) ?spin_loop: mov eax,1 lock xchg [mutex],eax or eax,eax jz ?lock_success xor ecx,ecx xor edx,edx lea eax,[mutex] monitor mwait jmp ?spin_loop ?lock_success: ret --------------------------------------------------------------------- Собственно spin-lock надо использлвать только на короткое время. В случае kernel программирования может возникнуть необходимость в IRQ safe версиях этих функций. Тогда они должны сохранить флаг прерывания, и запретить прерывания во время выполнения.
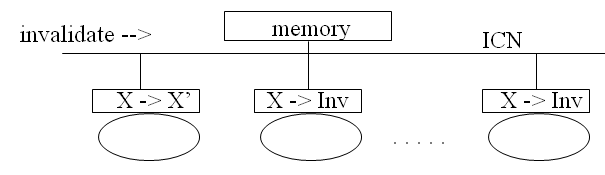
Оптимизация spin-locks С точки зрения кэширования Cache Coherence: Write-Invalidate:
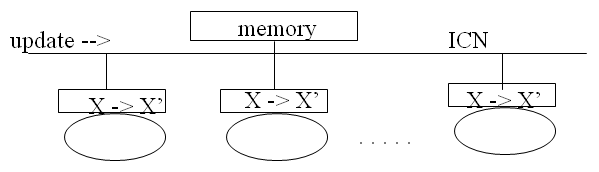
Write-Update
Spin on Test&Set - Test and Set захватывает шину - падает эффективность while(Test_and_Set(&lock) == BUSY) ; // spin Spin on Read + В основном обращения идут к cache - После того как кто-то отпускает lock, все начинают долбиться по Test_and_Set, это занимает много времени, особенно если у cache политика не обновлять внешние записи, а инвалидировать while(1) { while(lock == BUSY) ; // spin - чтение из cache if (Test_and_Set(&lock) == BUSY) break; } --------------------------------------------------------------------- spinmutex_lock(&mutex) ?spin_loop: cmp [mutex],0 ; From local cache jnz ?spin_loop mov eax,1 lock xchg [mutex],eax or eax,eax jz ?lock_success jmp ?spin_loop ?lock_success: ret ---------------------------------------------------------------------
Spin-lock pthread_spin_init pthread_spin_destroy pthread_spin_lock pthread_spin_trylock pthread_spin_unlock(pthread_spinlock_t* spiner);
Атомарные операции
Семафор
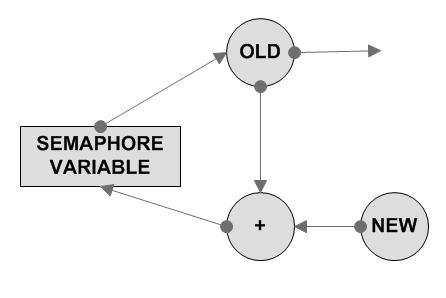
В настоящее время для поддержки семафоров в некоторых современных проессорах существуют специальные команды. Например для x86 такой командой является XADD XADD dest,src temp = src + dest src = dest dest = tmp операции -------- init первоначальная инициализация переменной семафора trylock попытка блокировки семафора - возращение статуса попытки lock блокировка семафора (собсвенно это spin-semaphore) unlock освобождение уже захваченного семафора ----------------------------------------------------------------------- semaphore_init(&semaphore) mov [semaphore], 0 ----------------------------------------------------------------------- bool semaphore_trylock(&semaphore) mov eax, 1 lock xadd [semaphore], eax cmp eax, MAX_VALUE mov eax, FALSE mov ebx, TRUE cmovc eax, ebx ret ----------------------------------------------------------------------- semaphore_unlock(&semaphore) lock dec [semaphore] ----------------------------------------------------------------------- соответсвенно захват ----------------------------------------------------------------------- spinsemaphore_lock(&semaphore) ?spin_loop mov eax,1 lock xadd [semaphore],eax cmp eax, MAX_VALUE jc ?lock_success ;; wait jmp ?spin_loop ?lock_success: ret ----------------------------------------------------------------------- реализация семафора на базе mutexa: ----------------------------------------------------------------------- bool semaphore_trylock(&semaphore) spinmutex_lock(&mutex) if (*semaphore < MAX_VALUE) { (*semaphore)++; mutex_unlock(&mutex); return TRUE; } mutex_unlock(&mutex); return FALSE; ----------------------------------------------------------------------- semaphore_unlock(&semaphore) spinmutex_lock(&mutex) (*semaphore)--; mutex_unlock(&mutex) ----------------------------------------------------------------------- spinsemaphore_lock(&semaphore) while(semaphore_trylock(&semaphore) != TRUE) ; -----------------------------------------------------------------------
RW-lock
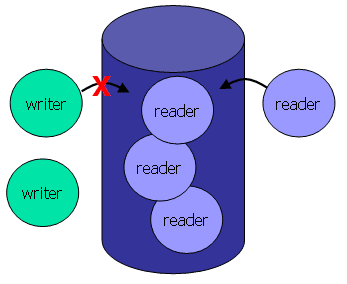
Писатель может быть только один (exclusive) Пока есть писатель другим нельзя ни читать не писать
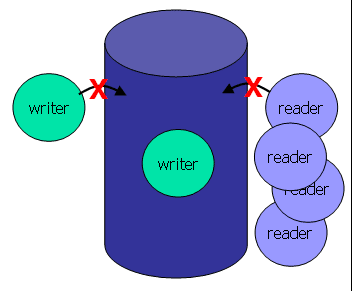
Сейчас мы будем рассматривать RW-spin-lock операции читатель писатель -------------------------------------------------------- init rwlock_init trylock reader_trylock writer_trylock lock reader_lock writer_lock unlock reader_unlock writer_unlock -------------------------------------------------------- Собственно одна из идей реализации - это хранить состояние RW-lock free read_acquired write_acquired и собственно говоря счетчик читателей ----------------------------------------------------------------------- rwlock_init(&rwlock) rwlock.state = RWLOCK_FREE; rwlock.rcount = 0; mutex_init(&mutex); ----------------------------------------------------------------------- bool reader_trylock(&rwlock) mutex_lock(&mutex); switch(rwlock.state) { case RWLOCK_FREE: rwlock.state = RWLOCK_READ_ACQUIRED; // fall throught case RWLOCK_READ_ACQUIRED: rwlock.rcount++; mutex_unlock(&mutex) return TRUE; default: // RWLOCK_WRITE_ACQUIRED mutex_unlock(&mutex); return FALSE; } ----------------------------------------------------------------------- reader_unlock(&rwlock) mutex_lock(&mutex) rwlock.rcount--; if (rwlock.rcount == 0) { rwlock.state = RWLOCK_FREE; } mutex_unlock(&mutex); ----------------------------------------------------------------------- reader_lock(&rwlock) while (reader_trylock(&rwlock) != TRUE) ; ----------------------------------------------------------------------- bool writer_trylock(&rwlock) mutex_lock(&mutex) if (rwlock.state != RWLOCK_FREE) { mutex_unlock(&mutex); return FALSE; } rwlock.state = RWLOCK_WRITE_ACQUIRED; mutex_unlock(&mutex); ----------------------------------------------------------------------- writer_unlock(&rwlock) mutex_lock(&mutex); rwlock.state = RWLOCK_FREE; mutex_unlock(&mutex); ----------------------------------------------------------------------- writer_lock(&rwlock) while (writer_trylock(&rwlock) != TRUE) ; ----------------------------------------------------------------------- чем такая имплементация плоха - если постоянно и часто идут чтения то writer может и не захватить RWlock, а как правило хочеться, чтобы он его все таки захватил. решается это добавлением дополнительного состояния "write pending", при котором новым читателям не дают возможность захватить rwlock, пока не будет записи. Дальнейшее развитие - уже сбалансированные политики. Собственно для однопроцессорных машин RWlock - это некоторый аналог spin-lock (если reader или writer вошел то пока не вышел ничего хорошего). Реальное преймущество RWlock идет в многопроцессорных машинах при паралельном чтении. Иногда бывает вариант, который имеет функуию upgrade_to_writer() которая превращает reader, который уже находиться внутри lockа, во writer.
собственно кроме RWlock бывает еще и RW-semaphore. Он имеет такую же семантику, но ограничение на количество одновременных читателей. Соответсвенно изменения касаются reader_trylock: ----------------------------------------------------------------------- bool reader_trylock(&rwlock) mutex_lock(&mutex); switch(rwlock.state) { case RWLOCK_FREE: rwlock.state = RWLOCK_READ_ACQUIRED; // fall throught case RWLOCK_READ_ACQUIRED: if (rwlock.rcount >= MAX_VALUE) { mutex_unlock(&mutex); return FASLE; } rwlock.rcount++; mutex_unlock(&mutex) return TRUE; default: // RWLOCK_WRITE_ACQUIRED mutex_unlock(&mutex); return FALSE; } -----------------------------------------------------------------------
Seq-lock
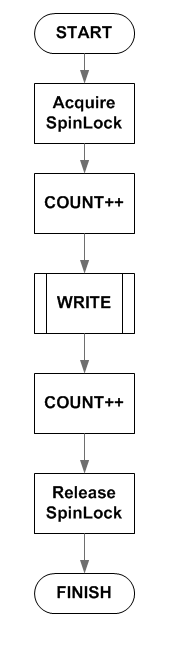
В результате семантика writera имеет вид: writer_seqlock(&seqlock); // WRITE actions writer_sequnlock(&seqlock); а семантика читателя: int seq; do { seq = reader_seqbegin(&seqlock); // READ actions } while( reader_seqretry(&seqlock, seq));
в общем виде spin операции не гарантируют доступ к ресурсу (может получиться так, что тот кто пришел позднее получил ресурс раньше). Что бы с этим бороться можно делать более сложные структуры которые будут содержать очереди. structures w/o pointers a-la statistics +-----------------+ | data | +-----------------+ | data | +-----------------+
Seq-lock cинхронизация и Out-Of-Order Execution Out-of-order execution: need barrier barrier is locked access LOCK xxx or special commands MFENCE SFENCE LFENCE на примере SeqLock прочитали LockCounter 1й раз прочитали данные прочитали LockCounter 2й раз поскольку Out-of-order execution то возможна ситуация типа прочитали LockCounter 1й раз прочитали LockCounter 2й раз прочитали данные что в общем то не то что мы хотели получить. что бы ее избежать делаем memory barrier по чтению прочитали LockCounter 1й раз прочитали данные Read Memory Barrier прочитали LockCounter 2й раз На самом деле их 2 типа Барьеры оптимизации (оптимизирующий компилятор переставляет) Барьеры памяти (процессор выполняет не в порядке)
wait-семантика
Mutex
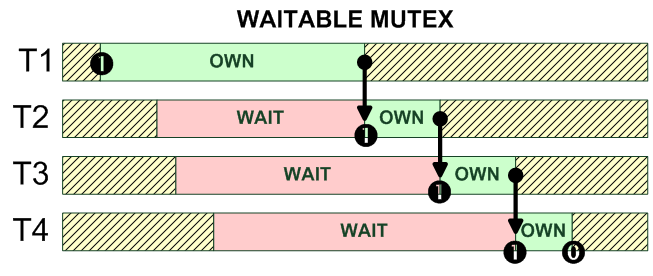
операции Win32 UNIX --------------------------------------------------------------- init CreateMutex() pthread_mutex_init() open OpenMutex() delete CloseHandle() pthread_mutex_destroy() trylock pthread_mutex_trylock() lock WaitForSingleObject() pthread_mutex_lock() unlock ReleaseMutex() pthread_mutex_unlock() --------------------------------------------------------------- ------------------------------------------------------------------- HANDLE CreateMutex(LPSECURITY_ATTRIBUTES lpMutexAttributes, BOOL bInitialOwner, LPCTSTR lpName); ------------------------------------------------------------------- HANDLE OpenMutex(DWORD dwDesiredAccess, BOOL bInheritHandle, LPCTSTR lpName); ------------------------------------------------------------------- BOOL ReleaseMutex(HANDLE hMutex); ------------------------------------------------------------------- DWORD WaitForSingleObject(HANDLE hHandle, DWORD dwMilliseconds); ------------------------------------------------------------------- Пример использования: HANDLE hMutex = CreateMutex(NULL, FALSE, NULL); if (hMutex == NULL) { // process errors } DWORD dwWriteResult = WaitForSingleObject(hMutex, 5000L); switch(dwWriteResult) { case WAIT_OBJECT_0: // here is code, which is protected by this mutex if (!ReleaseMutex(hMutex)) { // process errors } break; case WAIT_TIMEOUT: case WAIT_ABANDONED: // we not accqure mutex } CloseHandle(hMutex); ------------------------------------------------------------------- int pthread_mutex_init(pthread_mutex_t *restrict mutex, const pthread_mutexattr_t *restrict attr); ------------------------------------------------------------------- int pthread_mutex_destroy(pthread_mutex_t *mutex); ------------------------------------------------------------------- int pthread_mutex_trylock(pthread_mutex_t *mutex); ------------------------------------------------------------------- int pthread_mutex_lock(pthread_mutex_t *mutex); ------------------------------------------------------------------- int pthread_mutex_unlock(pthread_mutex_t *mutex); ------------------------------------------------------------------- int pthread_mutexattr_init int pthread_mutexattr_destroy(pthread_mutexattr_t* attr); pthread_mutexattr_set get prioceiling // priority of mutex owner protocol pshared // process shared recursive type protocol PTHREAD_PRIO_INHERIT PTHREAD_PRIO_PROTECT pshared PTHREAD_PROCESS_SHARED PTHREAD_PROCESS_PRIVATE recursive PTHREAD_RECURSIVE_ENABLE PTHREAD_RECURSIVE_DISABLE type PTHREAD_MUTEX_NORMAL PTHREAD_MUTEX_ERRORCHECK PTHREAD_MUTEX_RECURSIVE int pthread_mutex_init(pthread_mutex_t* mutex, const pthread_mutexattr_t* attr); int pthread_mutex_lock(pthread_mutex_t* mutex); int pthread_mutex_trylock(pthread_mutex_t* mutex); int pthread_mutex_timedlock(pthread_mutex_t* mutex, const struct timespec* abstimeout); // QNX int pthread_mutex_unlock(pthread_mutex_t* mutex); int pthread_mutex_destroy(pthread_mutex_t* mutex);
Semaphore
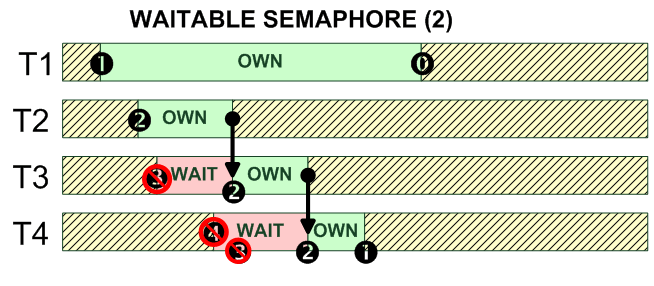
операции Win32 -------------------------------- init CreateSemaphore() open OpenSemaphore() delete CloseHandle() lock WaitForSingleObject() unlock ReleaseSemaphore() --------------------------------- ------------------------------------------------------------------- HANDLE CreateSemaphore(LPSECURITY_ATTRIBUTES lpSemaphoreAttributes, LONG lInitialCount, LONG lMaximumCount, LPCTSTR lpName); ------------------------------------------------------------------- HANDLE OpenSemaphore(DWORD dwDesiredAccess, BOOL bInheritHandle, LPCTSTR lpName); ------------------------------------------------------------------- BOOL ReleaseSemaphore(HANDLE hSemaphore, LONG lReleaseCount, LPLONG lpPreviousCount); ------------------------------------------------------------------- Семантика использования: Wait condition: // THREAD 1 // THREAD 2 while(!expr) expr = true; { post(&sem); wait(&sem) } Exclusive actions: // THREAD 1 // THREAD 2 wait(&sem); wait(&sem); // critical section // critical section post(&sem); post(&sem); Count semaphore: // THREAD 1 // THREAD 2 while(true) while(true) { { // action wait(&sem); post(&sem); // action } } UNIX/QNX semaphore.h int sem_init(sem_t* sem, int shared, unsigend int value); // Unnamed int sem_destroy(sem_t* sem); sem_open // Named (open or create) sem_close int sem_wait(sem_t* sem); int sem_trywait(sem_t* sem); int sem_timedwait(sem_t* sem, const timespec* abstimeout); int sem_post(sem_t* sem); int sem_getvalue(sem_t* sem, int* value); int sem_unlink(const char* name)
RWLock
Event
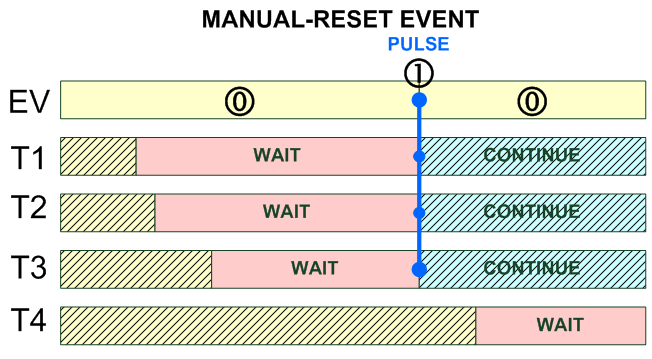
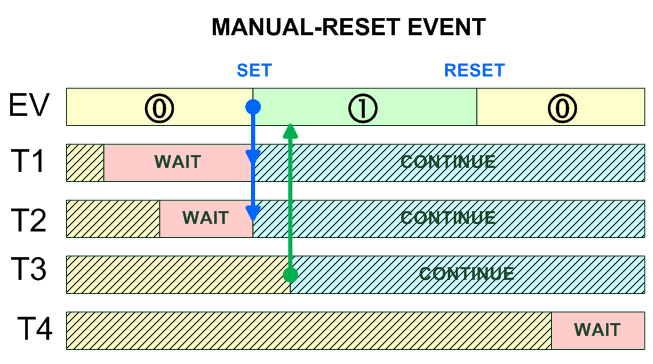
операции Win32 -------------------------------- init CreateEvent() open OpenEvent() delete CloseHandle() signaled SetEvent() PulseEvent() nonsignaled ResetEvent() wait WaitForSingleObject() -------------------------------- ------------------------------------------------------------------- HANDLE CreateEvent(LPSECURITY_ATTRIBUTES lpEventAttributes, BOOL bManualReset, BOOL bInitialState, LPCTSTR lpName); ------------------------------------------------------------------- HANDLE OpenEvent(DWORD dwDesiredAccess, BOOL bInheritHandle, LPCTSTR lpName); ------------------------------------------------------------------- BOOL PulseEvent(HANDLE hEvent); ------------------------------------------------------------------- BOOL SetEvent(HANDLE hEvent); ------------------------------------------------------------------- BOOL ResetEvent(HANDLE hEvent); -------------------------------------------------------------------
Conditional vars
Критические секции
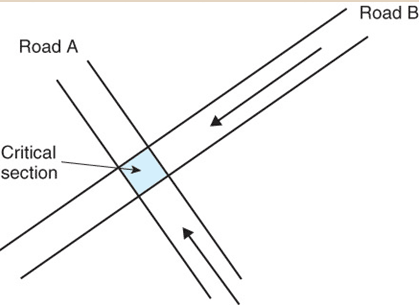
Критическая секция - кусок кода который будет выполняться без вытеснения
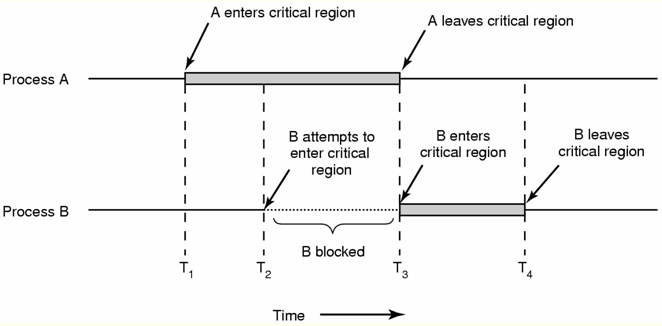
Собственно критическая секция: waitable_mutex_lock(&mutex); // Here is critical section itself waitable_mutex_unlock(&mutex); ------------------------------------------------------------------- void InitializeCriticalSection(LPCRITICAL_SECTION lpCriticalSection); ------------------------------------------------------------------- BOOL TryEnterCriticalSection(LPCRITICAL_SECTION lpCriticalSection); ------------------------------------------------------------------- void EnterCriticalSection(LPCRITICAL_SECTION lpCriticalSection); ------------------------------------------------------------------- void LeaveCriticalSection(LPCRITICAL_SECTION lpCriticalSection); ------------------------------------------------------------------- void DeleteCriticalSection(LPCRITICAL_SECTION lpCriticalSection); -------------------------------------------------------------------
барьеры
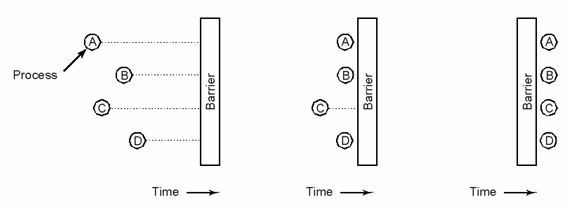
LockFree barrier: if (InterlockedIncrement(&ActiveThreads) == MaxThreads) { SetEvent(StartEvent); } else { WaitForSingleObject(StartEvent, INFINIFY); }
Реентерабильные семафоры и мьютексы