FP Addition
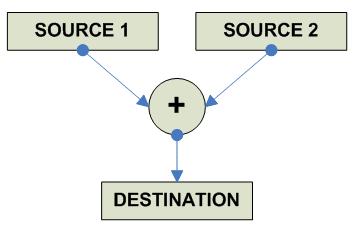
destination = source1 + source2 ------------------------------------------------------------------------------- o F.P Addition x86 FADD AR RA ---------------------------------------- Alpha ADDF RRR (F-floating) ADDG RRR (G-floating) ADDS RRR (S-floating) ADDT RRR (T-floating) ---------------------------------------- MIPS ADD.S 32 RRR ADD.D 64 RRR ----------------------------------------- SPARC FADDS RRR FADDD RRR FADDQ RRR ----------------------------------------- PPC FADDS 32 RRR FADD 64 RRR ----------------------------------------- HPPA FADDxx RRR ----------------------------------------- IA-64 FADD.pc.sf F1=F2,F3 (Pop: fma.pc.sf F1=F3,f1,F2) (Single) .s .s0 (Double) .d .s1 .s2 .s3 (Status Flags accessed) ------------------------------------------ 68K FADD.S [EA],FPn (Default rounding) FADD.D [EA],FPn FADD.X [EA],FPn FPm,FPn FrADD.f [EA],FPn (Specific Rounding) FrADD.X FPm,FPn S (round to single) D (round to double) ------------------------------------------- JVM FADD 32 DADD 64
FP Subtract
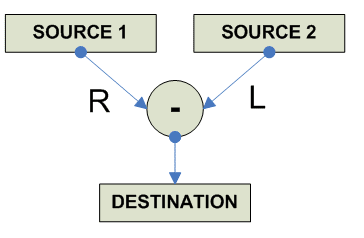
destination = source1 - source2 ------------------------------------------------------------------------------- o F.P. Subtraction x86 FSUB AR RA FSUBR AR RA (reverse operands) ----------------------------------------- Alpha SUBF RRR (F-floating) SUBG RRR (G-floating) SUBS RRR (S-floating) SUBT RRR (T-floating) ----------------------------------------- MIPS SUB.S RRR SUB.D RRR ----------------------------------------- SPARC FSUBS RRR FSUBD RRR FSUBQ RRR ----------------------------------------- PPC FSUB 64 RRR FSUBS 32 RRR ----------------------------------------- HPPA FSUBxx RRR ----------------------------------------- IA-64 FSUB.pc.sf F1=F3,F2 (pop: fms.pc.sf F1=F3,f1,F2) ------------------------------------------ 68K FSUB.S [EA],FPn (Default rounding) FSUB.D [EA],FPn FSUB.X [EA],FPn FPm,FPn FrSUB.f [EA],FPn (Specific Rounding) FrSUB.X FPm,FPn S (round to single) D (round to double) ------------------------------------------- JVM FSUB 32 DSUB 64
FP Multiply
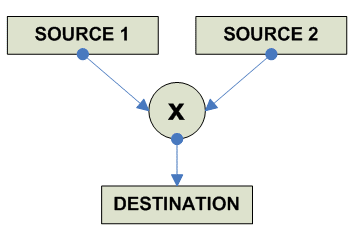
destination = source1 * source2 ------------------------------------------------------------------------------- o F.P. Multiply x86 FMUL AR RA ----------------------------------------- Alpha MULF RRR (F-floating) MULG RRR (G-floating) MULS RRR (S-floating) MULT RRR (T-floating) ----------------------------------------- MIPS MUL.S RRR MUL.D RRR ----------------------------------------- SPARC FMULS RRR FMULD RRR FMULQ RRR ----------------------------------------- PPC FMUL 64 RRR FMULS 32 RRR ----------------------------------------- HPPA FMPYxx RRR XMPYUxx RRR (Fixed Point Unsigned Multiply) ----------------------------------------- IA-64 FMPY.pc.sf F1=F3,F4 (pop:fma.pc.sf F1=F3,F4,f0) ------------------------------------------ 68K FMUL.S [EA],FPn (Default rounding) FMUL.D [EA],FPn FMUL.X [EA],FPn FPm,FPn FrMUL.f [EA],FPn (Specific Rounding) FrMUL.X FPm,FPn S (round to single) D (round to double) FSGLMUL.F [EA],FPn (Single Precension) FSGLMUL.X FPm,FPn ------------------------------------------- JVM FMUL 32 DMUL 64
FP Divide
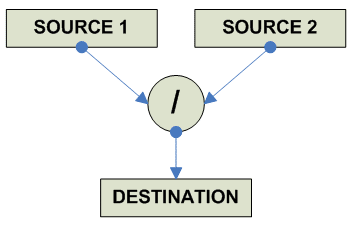
destination = source1 / source2 ------------------------------------------------------------------------------- o F.P. Divide x86 FDIV AR RA FDIVR AR RA (reverse operands) ----------------------------------------- Alpha DIVF RRR (F-floating) DIVG RRR (G-floating) DIVS RRR (S-floating) DIVT RRR (T-floating) ----------------------------------------- MIPS DIV.S RRR (S) DIV.D RRR (D) ----------------------------------------- SPARC FDIVS RRR FDIVD RRR FDIVQ RRR ----------------------------------------- PPC FDIV 64 RRR FDIVS 32 RRR ----------------------------------------- HPPA FDIV RRR ------------------------------------------ 68K FDIV.S [EA],FPn (Default rounding) FDIV.D [EA],FPn FDIV.X [EA],FPn FPm,FPn FrDIV.f [EA],FPn (Specific Rounding) FrDIV.X FPm,FPn S (round to single) D (round to double) FSGLDIV.F [EA],FPn (Single Precension) FSGLDIV.X FPm,FPn ------------------------------------------- JVM FDIV 32 DDIV 64
FP Remainder
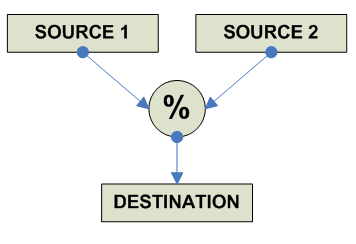
destination = source1 % source2 ------------------------------------------------------------------------------- o F.P. Remainder x86 FPREM AF ----------------------------------------- Alpha (*) Complex sequence ----------------------------------------- MIPS (*) Complex sequence ----------------------------------------- SPARC (*) Complex sequence ----------------------------------------- PPC (*) Complex sequence ------------------------------------------- JVM FEM 32 DREM 64
FP Absolute Value
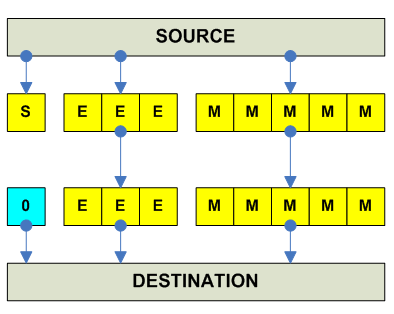
destination = |source| Negative absolute value:
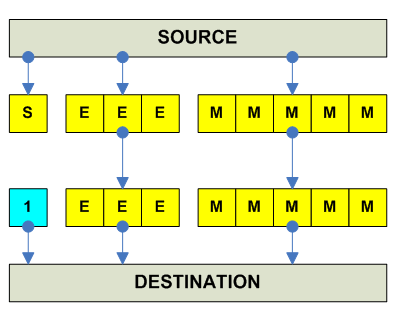
destination = - |source| ------------------------------------------------------------------------------- o F.P. Absolute Value x86 FABS A ----------------------------------------- Alpha CPYS RRR (Copy Sign) (from positive number f31) ----------------------------------------- MIPS ABS.S 32 RR ABS.D 64 RR ----------------------------------------- SPARC FABSS RR FABSD RR V9 FABSQ RR V9 ----------------------------------------- PPC FABS RR ----------------------------------------- HPPA FABSxx RR ----------------------------------------- IA-64 FABS 64 F1=F2 (Pop: fmerge.s F1=f0,F2) ------------------------------------------ 68K FABS.S [EA],FPn (Default rounding) FABS.D [EA],FPn FABS.X [EA],FPn FPm,FPn FPn FrABS.f [EA],FPn (Specific Rounding) FrABS.X FPm,FPn FrABS.X FPn S (round to single) D (round to double) ----------------------------------------- JVM (*) Complex Sequence
FP Negate
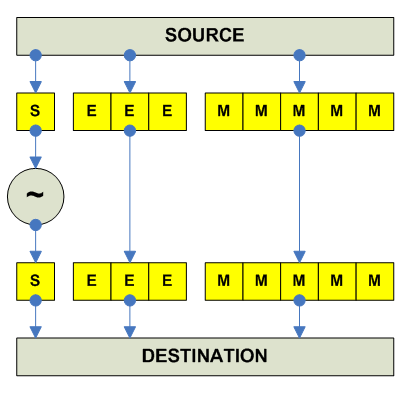
destination = -source ------------------------------------------------------------------------------- o F.P. Negate (Change sign) x86 FCHS A ----------------------------------------- Alpha CPYSN RRR (Copy Sign Negative, all 3 registers is same) ----------------------------------------- MIPS NEG.S RR NEG.D RR ----------------------------------------- SPARC FNEGS RR FNEGD RR V9 FNEGQ RR V9 ----------------------------------------- PPC FNEG RR ----------------------------------------- IA-64 FNEG F1=F3 (Pop: fmerge.ns F1=F3,F3) ------------------------------------------ 68K FNEG.S [EA],FPn (Default rounding) FNEG.D [EA],FPn FNEG.X [EA],FPn FPm,FPn FPn FrNEG.f [EA],FPn (Specific Rounding) FrNEG.X FPm,FPn FrNEG.X FPn S (round to single) D (round to double) ------------------------------------------ JVM FNEG 32 DNEG 64
FP Square Root
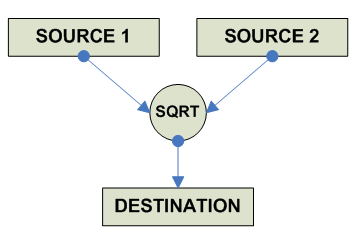
________ / destination = V source ------------------------------------------------------------------------------- o F.P. Square Root x86 FSQRT A ----------------------------------------- Alpha (*) Complex sequence ----------------------------------------- MIPS SQRT.S RR SQRT.D RR ----------------------------------------- SPARC FSQRTS RR FSQRTD RR FSQRTQ RR ----------------------------------------- PPC FSQRT 64 RR FSQRTS 32 RR ----------------------------------------- HPPA FSQRTxx RR ----------------------------------------- IA-64 (*) Complex Algorithm based on FRSQRTA.sf F1,P2=F3 (Reciprocal Square Root Approximation) ----------------------------------------- 68K FSQRT.S [EA],FPn (Default rounding) FSQRT.D [EA],FPn FSQRT.X [EA],FPn FPm,FPn FPn FrSQRT.f [EA],FPn (Specific Rounding) FrSQRT.X FPm,FPn FrSQRT.X FPn S (round to single) D (round to double) -------------------------------------------------------------------------------
FP Multiply-Add/Multiply-Subtract
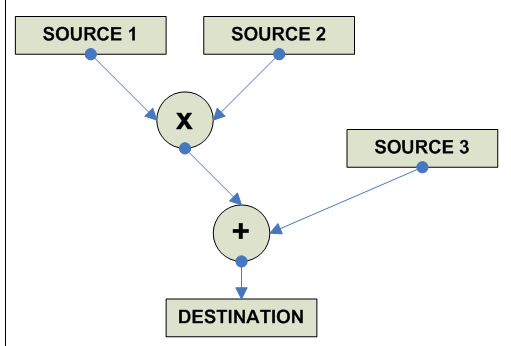
destination = (source1 * source2) + source3 Multiply Subtract:
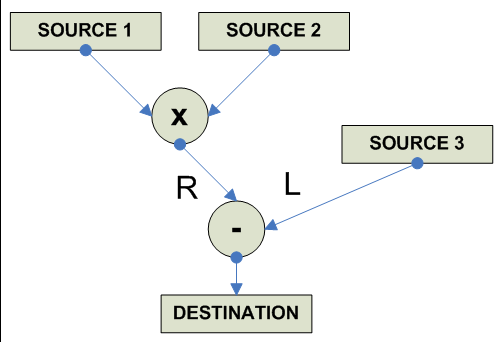
destination = (source1 * source2) - source3 Negative Multiply Add:
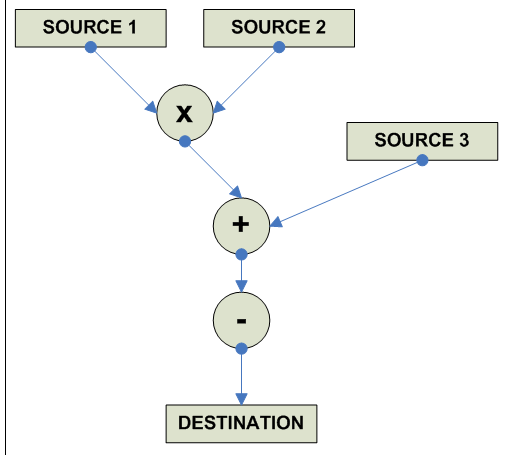
destination = - [(source1 * source2) + source3] Negative Multiply Subtract
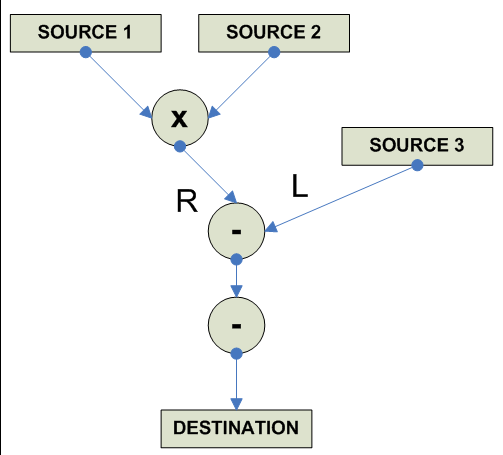
destination = - [(source1 * source2) - source3] ------------------------------------------------------------------------------- o F.P. Multiply/Add joined operation x86 ----------------------------------------- Alpha ----------------------------------------- MIPS MADD.S RRRR (addition) MADD.D RRRR d <- (a*b)+c MSUB.S RRRR (subtraction) MSUB.D RRRR d <- (A*b)-c NMADD.S RRRR (all MIPS IV) NMADD.D RRRR d <- -(a*b+c) NMSUB.S RRRR NMSUB.D RRRR d <- -(a*b-c) ----------------------------------------- PPC FMADD 64 RRRR d <- (a*b) + c FMADDS 32 RRRR FMSUB 64 RRRR d <- (a*b) - c FMSUBS 32 RRRR FNMADD 64 RRRR d <- -(a*b+c) FNMADDS 32 RRRR FNMSUB 64 RRRR d <- -(a*b-c) FNMSUBS 32 RRRR ----------------------------------------- SPARC (??) ----------------------------------------- HPPA FMPYADD RRRRR c <- (a * b); e <- (e + a); FMPYSUB RRRRR c <- (a * b); e <- (e - a); ----------------------------------------- IA-64 FMA.pc.sf F1=F3,F4,F2 Multiply Add FMS.pc.sf F1=F3,F4,F2 Multiply Subtract
FP Maximum/Minimum/Absolute Maximum/Absolute Maximum
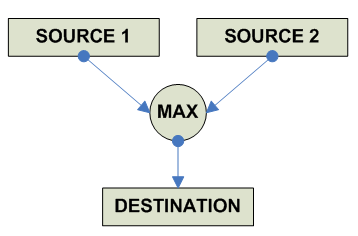
destination = (source1 > source2): source1 : source2
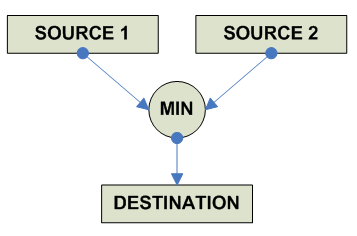
destination = (source1 < source2): source1 : source2
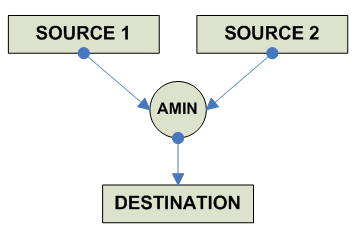
destination = (|source1| < |source2|) source1 : source2
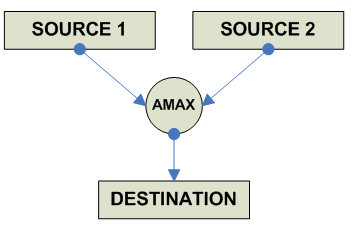
destination = (|source1| > |source2|) source1 : source2
THIS SECTION IS UNDER CONSTRUCTION
FP Move
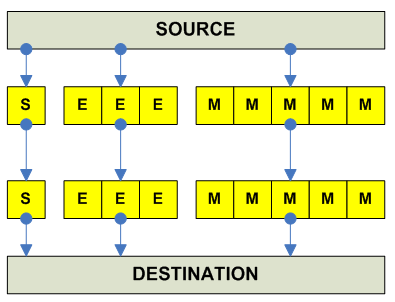
------------------------------------------------------------------------------- o Move F.P. regsiter x86 (*) Complex sequence ----------------------------------------- Alpha FCPYSE RRR (the last two register is same) ----------------------------------------- MIPS MOV.S RR MOV.D RR ----------------------------------------- SPARC FMOVS RR FMOVD RR V9 FMOVQ RR V9 ----------------------------------------- PPC FMR RR ----------------------------------------- HPPA FCPYxx RR ----------------------------------------- IA-64 MOV F1=F3 (Pop: fmerge.s F1=F3,F3)
------------------------------------------------------------------------------- o F.P. Extract Exponent and Significand x86 FXTRACT AF ----------------------------------------- Alpha FCPYSE RRR (copy sign and exponent from two different registers) ----------------------------------------- MIPS ----------------------------------------- PPC ----------------------------------------- IA-64 GETF.S R1=F1 (Single form) .D R1=F1 (Double form) .EXP R1=F1 (Exponent form) .SIG R1=F1 (Significand form) (back operation is:) SETF.S/D/EXP/SIG F1=R1 ------------------------------------------------------------------------------- o F.P. Scale x=x*2^y x86 FSCALE AF ----------------------------------------- Alpha ----------------------------------------- MIPS ----------------------------------------- PPC ------------------------------------------------------------------------------- o Exhange F.P registers x86 FXCH AR ----------------------------------------- Alpha ----------------------------------------- MIPS ----------------------------------------- PPC
FP Load
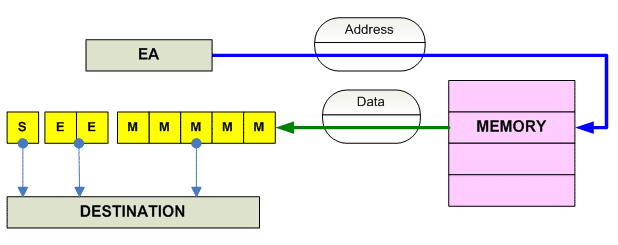
------------------------------------------------------------------------------- o Load Single-precension (32-bit) F.P x86 FLD AM ----------------------------------------- Alpha LDF R[RA+Disp] (F-,VAX-format) LDS R[RA+Disp] (S-,IEEE-format) ----------------------------------------- MIPS LWC1 32 R[R+Disp] LWXC1 32 R[Ra+Ridx] ----------------------------------------- SPARC LDF 32? R[Ra+Ra/Disp] ----------------------------------------- PPC LFS R[RA+Disp] LFSU R[RA+Disp] (update Address) LFSUX R[Ra+Ridx] (update address) LFSX R[Ra+Ridx] ----------------------------------------- HPPA FLDWXxx R(scaleR)R (indexed) FLDWSxx R(RDisp5)R (short) ------------------------------------------ IA-64 LDFS.fldtype.ldhint F1 = [R3] (no base update) LDFS.fldtype.ldhint F1 = [R3],R2 (base update) LDFS.fldtype.ldhint F1 = [R3],I9 (imm base update) (PAIR) LDFPS.fldtype.ldhint F1,F2 = [R3] (no base update) F1,F2 = [R3], 8 (base update) ------------------------------------------ 68K FMOVE.S [EA],FPn ------------------------------------------ JVM FALOAD (Array) FLOAD_0 FLOAD_1 FLOAD_2 FLOAD_3 FLOAD FRAME_PTR ------------------------------------------------------------------------------- o Load Doble-precension (64-bit) F.P. x86 FLD AM ----------------------------------------- Alpha LDG R[RA+Disp] (G-,VAX-format) LDT R[RA+Disp] (T-,IEEE-format) ----------------------------------------- MIPS LDC1 64 R[R+Disp] LDXC1 64 R[Ra+Ridx] ----------------------------------------- SPARC LDDF 64? R[Ra+Ra/Disp] ----------------------------------------- PPC LFD R[RA+Disp] LFDU R[RA+Disp] (update Address) LFDUX R[Ra+Ridx] (update address) LFDX R[Ra+Ridx] ----------------------------------------- HPPA FLDDXxx R(scaleR)R FLDDSxx R(RDisp5)R (short) ------------------------------------------ IA-64 LDFD.fldtype.ldhint F1 = [R3] (no base update) LDFD.fldtype.ldhint F1 = [R3],R2 (base update) LDFD.fldtype.ldhint F1 = [R3],I9 (imm base update) (PAIR) LDFPD.fldtype.ldhint F1,F2 = [R3] (no base update) F1,F2 = [R3], 16 (base update) ------------------------------------------ 68K FMOVE.D [EA],FPn ------------------------------------------ JVM DALOAD (Array) DLOAD_0 DLOAD_1 DLOAD_2 DLOAD_3 DLOAD FRAME_PTR ------------------------------------------------------------------------------- o Load Extended-precension F.P. x86 FLD AM (80-bit) ----------------------------------------- Alpha ----------------------------------------- MIPS ----------------------------------------- SPARC LDQF ? R[Ra+Ra/Disp] ----------------------------------------- PPC ------------------------------------------ IA-64 LDFE.fldtype.ldhint F1 = [R3] (no base update) LDFE.fldtype.ldhint F1 = [R3],R2 (base update) LDFE.fldtype.ldhint F1 = [R3],I9 (imm base update) ------------------------------------------ 68K FMOVE.X [EA],FPn
FP Store
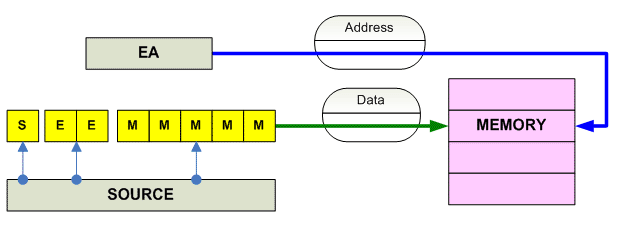
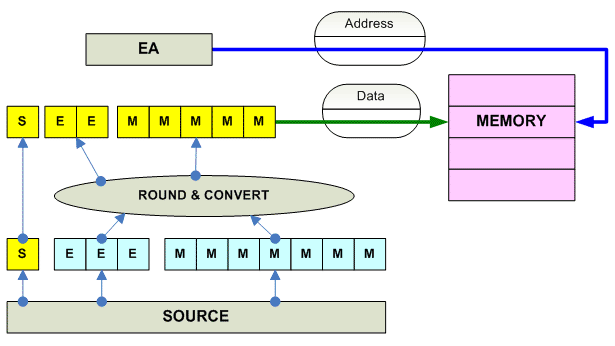
------------------------------------------------------------------------------- o Store Single-precension (32-bit) F.P x86 FST AM ----------------------------------------- Alpha STF R[RA+Disp] (F-,VAX-format) STS R[RA+Disp] (S-,IEEE-format) ----------------------------------------- MIPS SWC1 R[RA+Disp] SWXC1 R[Ra+Disp] ----------------------------------------- SPARC STF ? R[Ra+Ra/Disp] ----------------------------------------- PPC STFS R[RA+Disp] STFSU R[RA+Disp] (update Address) STFSUX R[Ra+Ridx] (update address) STFSX R[Ra+Ridx] ----------------------------------------- HPPA FSTWXxx RR(scaleR) FSTWSxx R(RDisp5)R (short) ----------------------------------------- IA-64 STFS.sthint [R3] = F2 (no-update base) [R3] = F2, I9 (update base) ------------------------------------------ 68K FMOVE.S FPn,[EA] ------------------------------------------ JVM FASTORE (Array) FSTORE_0 FSTORE_1 FSTORE_2 FSTORE_3 FSTORE VAR_IDX ------------------------------------------------------------------------------- o Store Doble-precension (64-bit) F.P. x86 FST AM ----------------------------------------- Alpha STG R[RA+Disp] (G-,VAX-format) STT R[RA+Disp] (T-,IEEE-format) ----------------------------------------- MIPS SDC1 R[Ra+Disp] SDXC1 R[Ra+Ridx] ----------------------------------------- SPARC STDF ? R[Ra+Ra/Disp] ----------------------------------------- PPC STFD R[RA+Disp] STFDU R[RA+Disp] (update Address) STFDUX R[Ra+Ridx] (update address) STFDX R[Ra+Ridx] ----------------------------------------- HPPA FSTDXxx RR(scaleR) (indexed) FSTDSxx R(RDisp5)R (short) ----------------------------------------- IA-64 STFD.sthint [R3] = F2 (no-update base) [R3] = F2, I9 (update base) ------------------------------------------ 68K FMOVE.D FPn,[EA] ------------------------------------------ JVM DASTORE (Array) DSTORE_0 DSTORE_1 DSTORE_2 DSTORE_3 DSTORE VAR_IDX ------------------------------------------------------------------------------ o Store Extended-precension F.P. x86 FST AM (80-bit) ----------------------------------------- Alpha ----------------------------------------- MIPS ----------------------------------------- SPARC STQF ? R[Ra+Ra/Disp] ----------------------------------------- PPC ----------------------------------------- IA-64 STFE.sthint [R3] = F2 (no-update base) [R3] = F2, I9 (update base) ------------------------------------------ 68K FMOVE.X FPn,[EA]
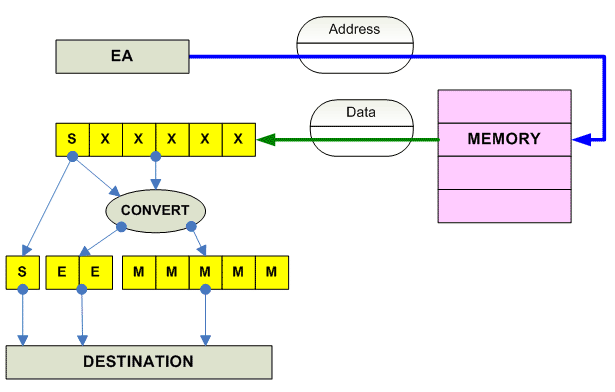
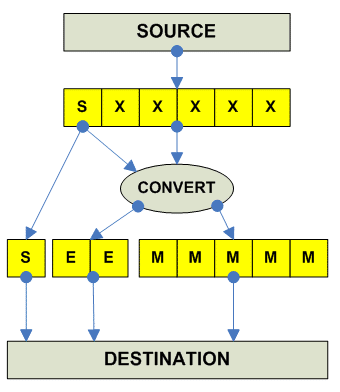
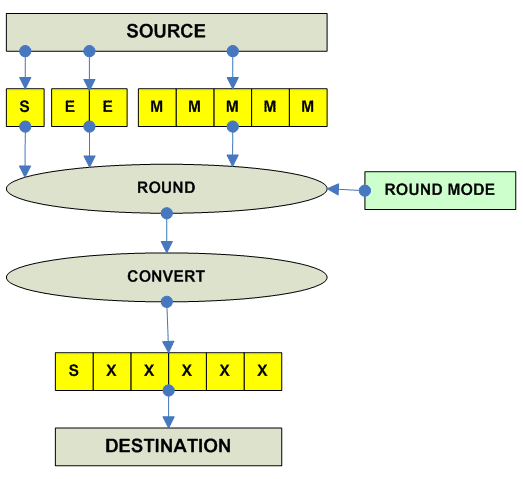
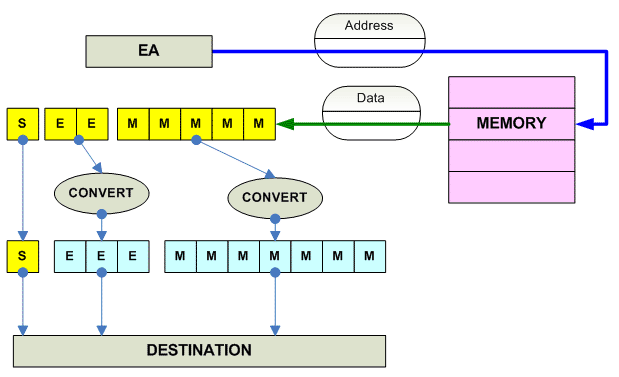
Convert between FP Formats
FP Branch/Compare
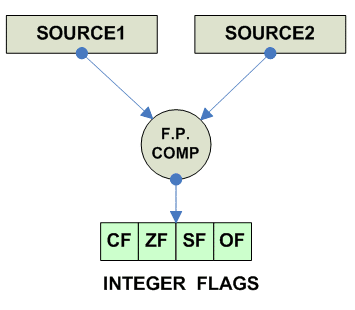
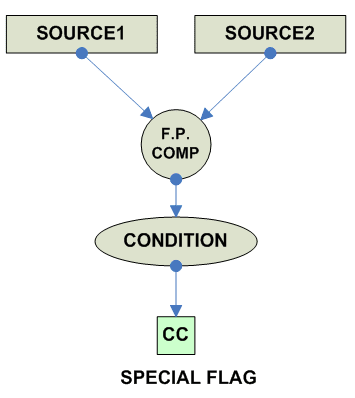
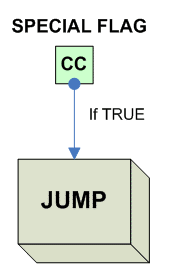
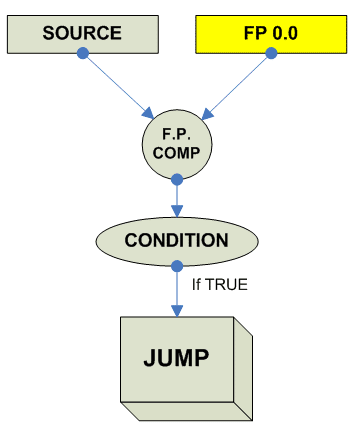
Условия для блоков с плавающей точкой Для старых архитектур (особенно CISC) характерно, что блок с плавающей точкой был встроен в сопроцессор, поэтому как правило отсутсвуют непосредственные переходы по условиям с плавающей точкой. Что бы их реализовать надо загрузить слово состояния FP из сопроцессора в процессор, а потом его анализировать. Типичный пример: x86: fnstsw ax ; читаем FP. SW в AX sahf ; записываем AX в регистр флагов ; готовы делать переходы по FP MIPS: C.cond.S C.cond.D Потом появились и более позднии варианты которые пишут integer флаги напрямую, что позволяет пользоваться стандартными branches. x86: fcomi st,st(2) ; например