35.2.3. ЦЕЛОЧИСЛЕННЫЕ ВЕКТОРНЫЕ КОММАНДЫ
Vector Paralel Addition
Обычный:
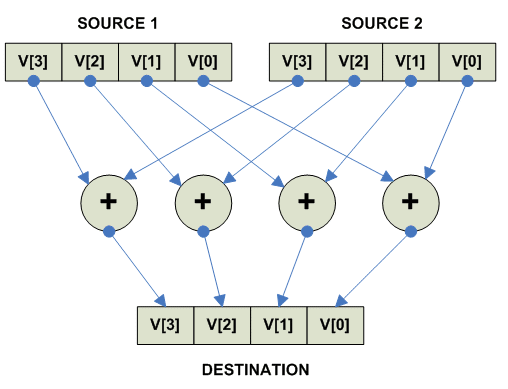
parellel
{
destination[i] = source1[i] + source2[i]
}
|
Unsigned Saturate:
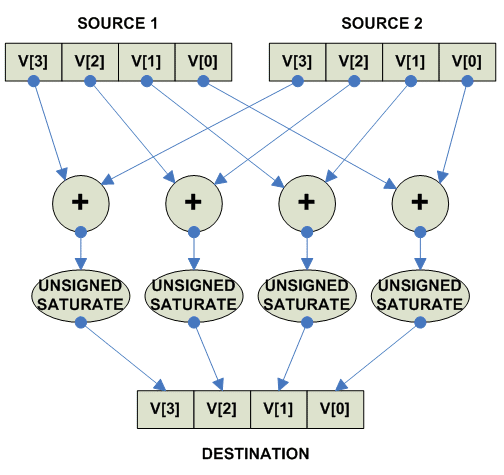
parellel
{
destination[i] = Unsigned_Saturate(source1[i] + source2[i])
}
|
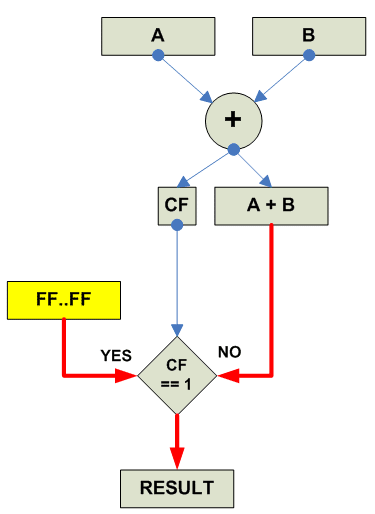
Собственно действия при unsigned saturated add:
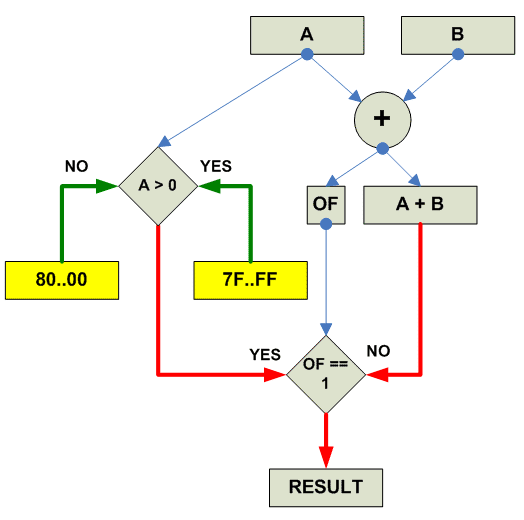
Add saturated unsigned:
Signed Saturate:
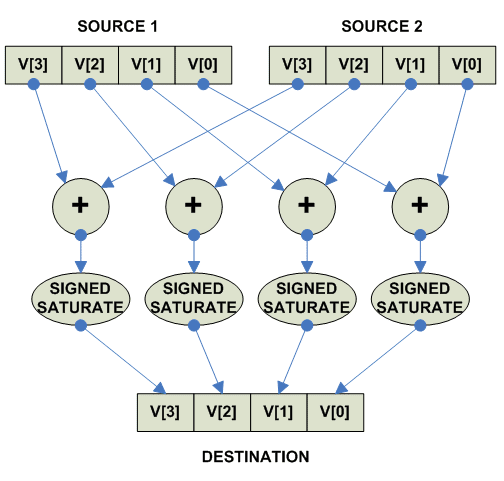
parellel
{
destination[i] = Signed_Saturate(source1[i] + source2[i])
}
|
Собственно действия при signed saturated add:
Add saturated signed:
---------------------------------------------------------------------------
VECTOR ADDITION
--------------------------------------------------------------------
64 64 64 64 128 128 128 128 128
8xB 4xW 2xD 1xQ 16xB 8xW 4xD 2xQ 1xO
--------------------------------------------------------------------
x86 PADDB PADDW PADDD PADDQ PADDB PADDW PADDD PADDQ
PADDSB PADDSW PADDSB PADDSW
PADDUSB PADDUSW PADDUSB PADDUSW
--------------------------------------------------------------------
ia64 PADD1 PADD2 PADD4
(.uuu)
(.uus)
(.ssi)
--------------------------------------------------------------------
Alpha
--------------------------------------------------------------------
MIPS ADD.OB ADD.QH
--------------------------------------------------------------------
PPC VADDSBS VADDSHS VADDSWS
VADDUBM VADDUHM VADDUWM
VADDUBS VADDUHS VADDUWS
--------------------------------------------------------------------
SPARC FPADD16 FPADD32
---------------------------------------------------------------------------
Vector parallel subtraction
Обчыный:
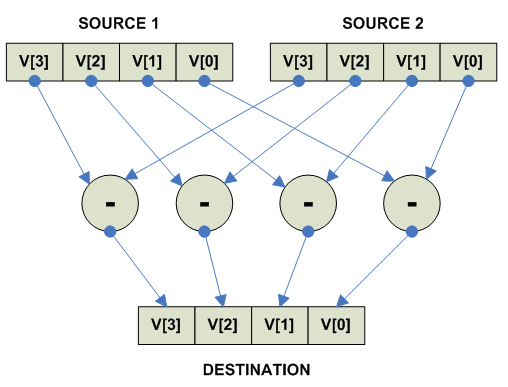
parellel
{
destination[i] = source1[i] - source2[i]
}
|
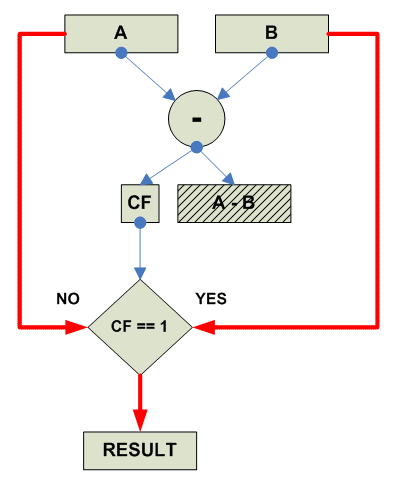
Unsigned Saturate:
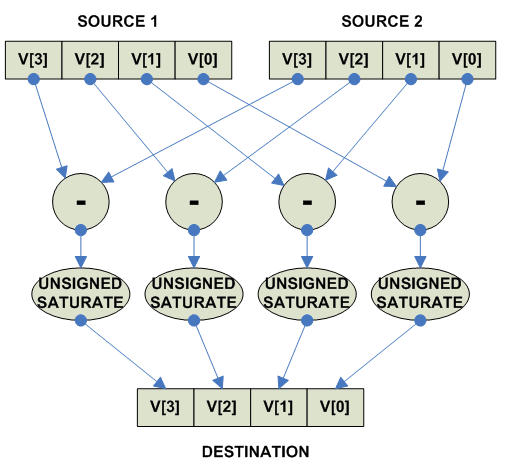
parellel
{
destination[i] = Unsigned_Saturate(source1[i] + source2[i])
}
|
Собственно действия при unsigned saturated subtract:
Subtract saturated unsigned:
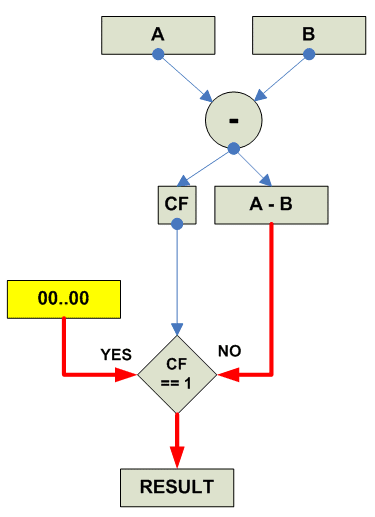
Signed Saturate:
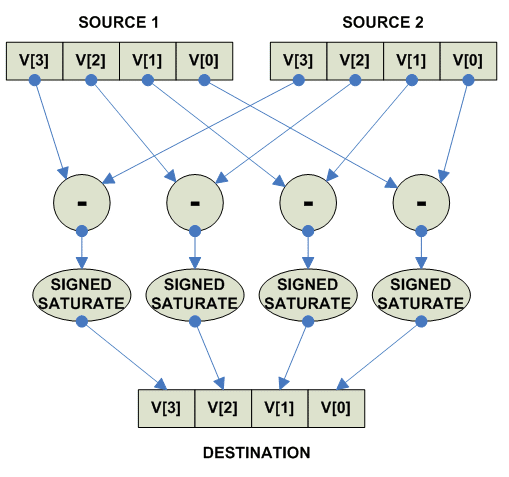
parellel
{
destination[i] = Signed_Saturate(source1[i] + source2[i])
}
|
Собственно действия при signed saturated subtract:
Subtract saturated signed:
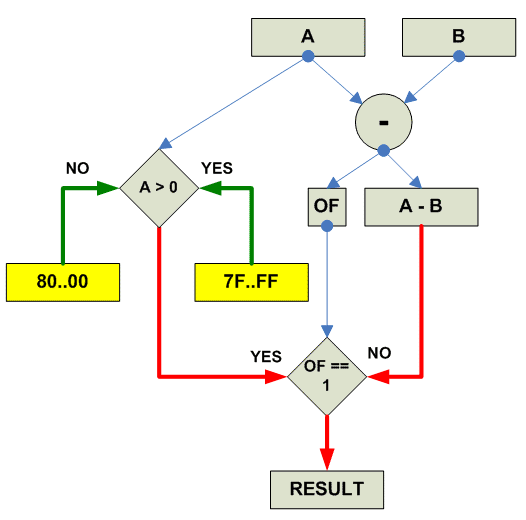
---------------------------------------------------------------------------
VECTOR SUBTRACTION
--------------------------------------------------------------------
64 64 64 64 128 128 128 128 128
8xB 4xW 2xD 1xQ 16xB 8xW 4xD 2xQ 1xO
--------------------------------------------------------------------
x86 PSUBB PSUBW PSUBD PSUBQ PSUBB PSUBW PSUBD PSUBQ
PSUBSB PSUBSW PSUBSB PSUBSW
PSUBUSB PSUBUSW PSUBUSB PSUBUSW
--------------------------------------------------------------------
ia64 PSUB1 PSUB2 PSUB4
(.uuu)
(.uus)
(.sss)
--------------------------------------------------------------------
Alpha
--------------------------------------------------------------------
MIPS SUB.OB SUB.QH
--------------------------------------------------------------------
PPC VSUBSBS VSUBSHS VSUBSWS
VSUBUBM VSUBUHM VSUBSWM
VSUMUBS VSUBUHS VSUMSWS
--------------------------------------------------------------------
SPARC FPSUB16 FPSUB32
---------------------------------------------------------------------------
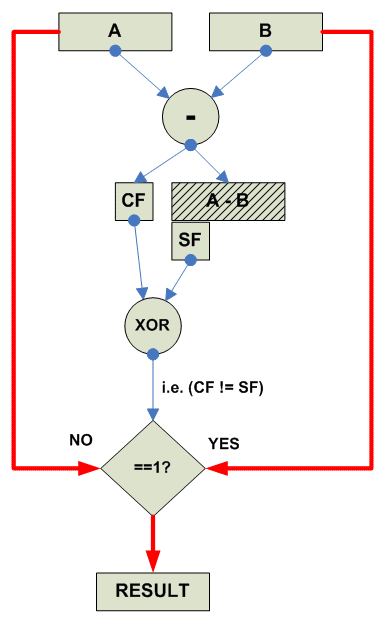
Vector parallel maximum
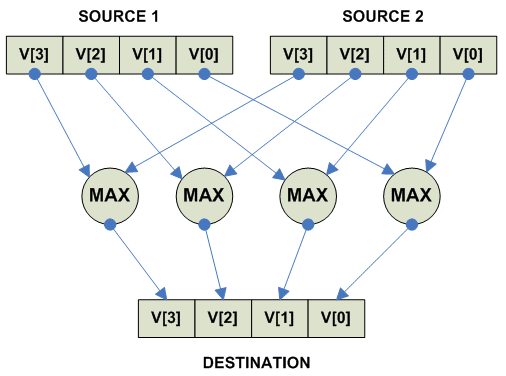
Операция MAX имеет два различных варианта для Signed и Unsigned чисел.
parellel
{ U
destination[i] = (source1[i] >= source2[i])? source1[i] : source2[i]
}
parellel
{ S
destination[i] = (source1[i] >= source2[i])? source1[i] : source2[i]
}
|
Собственно действия при maximum:
Unsigned Maximum:
Signed Maximum:
---------------------------------------------------------------------------
VECTOR MAXIMUM
--------------------------------------------------------------------
64 64 64 64 128 128 128 128 128
8xB 4xW 2xD 1xQ 16xB 8xW 4xD 2xQ 1xO
--------------------------------------------------------------------
x86 PMAXUB PMAXSW PMAXUB PMAXSW
--------------------------------------------------------------------
ia64 PMAX1 PMAX2
--------------------------------------------------------------------
Alpha MAXUB8 MAXUW4
MAXSB8 MAXSW4
--------------------------------------------------------------------
MIPS MAX.OB MAX.QH
--------------------------------------------------------------------
PPC VMAXSB VMAXSH VMAXSW
VMAXUB VMAXUH VMAXUW
--------------------------------------------------------------------
SPARC
---------------------------------------------------------------------------
Vector parallel minimum
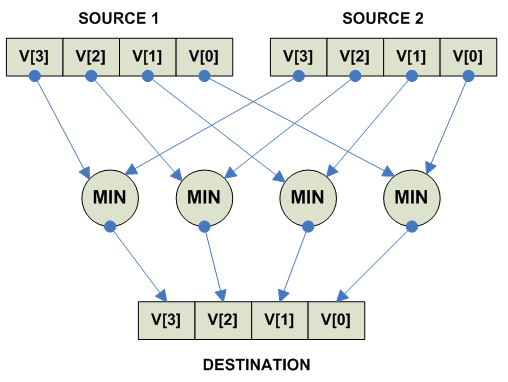
Операция MIN имеет два различных варианта для Signed и Unsigned чисел.
parellel
{ U
destination[i] = (source1[i] < source2[i])? source1[i] : source2[i]
}
parellel
{ S
destination[i] = (source1[i] < source2[i])? source1[i] : source2[i]
}
|
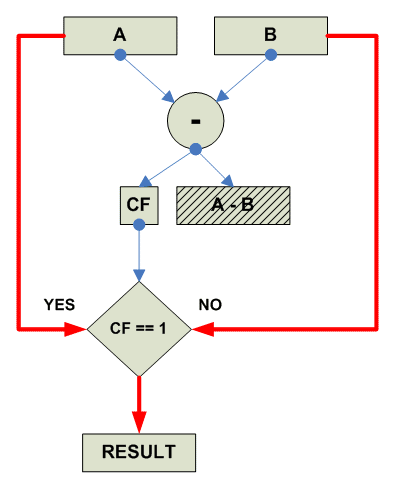
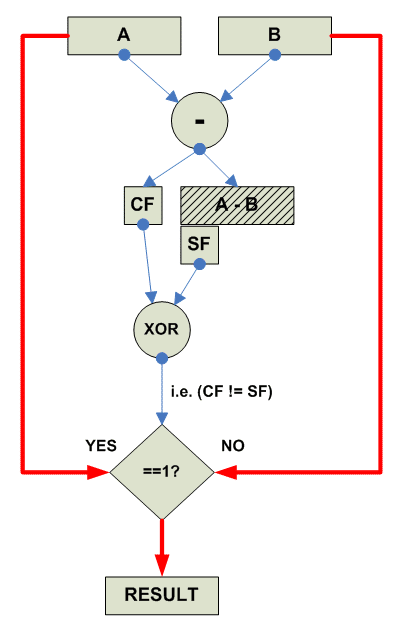
Собственно действия при manimum:
Unsigned Manimum:
Signed Manimum:
---------------------------------------------------------------------------
VECTOR MINIMUM
--------------------------------------------------------------------
64 64 64 64 128 128 128 128 128
8xB 4xW 2xD 1xQ 16xB 8xW 4xD 2xQ 1xO
--------------------------------------------------------------------
x86 PMINUB PMINSW PMINUB PMINUW
--------------------------------------------------------------------
ia64 PMIN1 PMIN2
--------------------------------------------------------------------
Alpha MINUB8 MINUW4
MINSB8 MINSW4
--------------------------------------------------------------------
MIPS MIN.OB MIN.QH
--------------------------------------------------------------------
PPC VMINSB VMINSH VMINSW
VMINUB VMINUH VMINUW
--------------------------------------------------------------------
SPARC
---------------------------------------------------------------------------
Vector parallel average sum
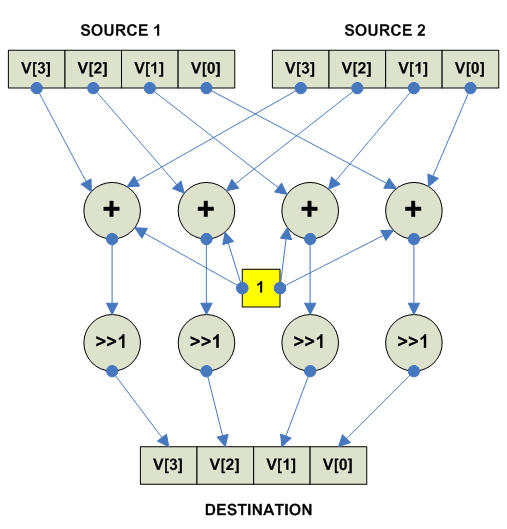
Собственно Average - операция одна и таже для знаковых и беззнаковых чисел.
parellel
{
destination[i] = (source1[i] + source2[i] + 1) >> 1
}
|
Собственно действия при average:
(вообще говоря существуют два варианта - какой из них имплементирован
зависит от архитектуры).
Round to odd:
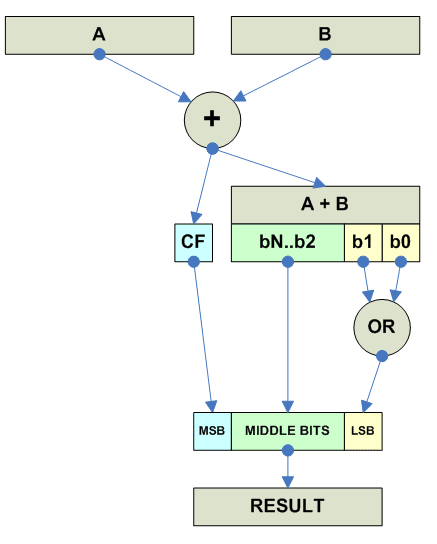
Round away from zero:
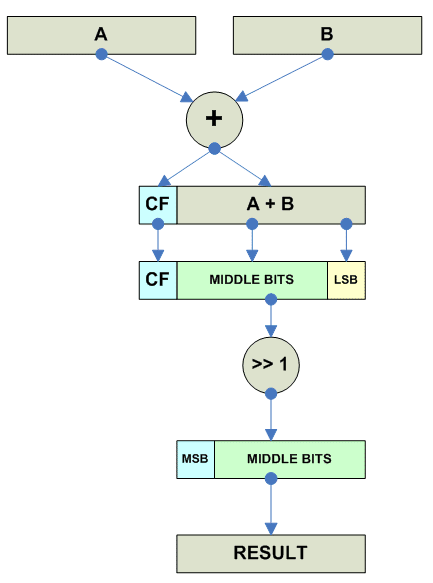
---------------------------------------------------------------------------
VECTOR AVERAGE SUM
--------------------------------------------------------------------
64 64 64 64 128 128 128 128 128
8xB 4xW 2xD 1xQ 16xB 8xW 4xD 2xQ 1xO
--------------------------------------------------------------------
x86 PAVGB PAVGW PAVGB PAVGW
--------------------------------------------------------------------
ia64 PAVG1 PAVG2
--------------------------------------------------------------------
Alpha
--------------------------------------------------------------------
MIPS
--------------------------------------------------------------------
PPC VAVGSB VAVGSH VAVGSW
VAVGUB VAVGUH VAVGUW
--------------------------------------------------------------------
SPARC
---------------------------------------------------------------------------
Vector Bitwise Logical Operations
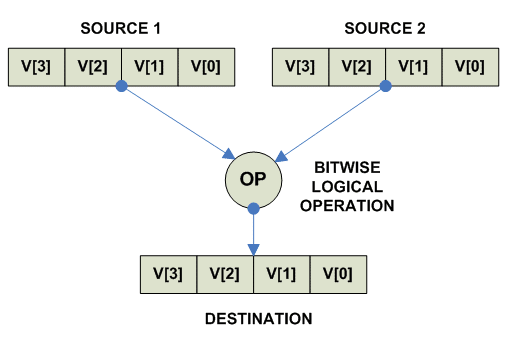
destination = source1 .LOGICAL_OP. source2
|
---------------------------------------------------------------------------
VECTOR BINARY LOGIC OPERATION (ALL)
--------------------------------------------------------------------
64 64 64 64 128 128 128 128 128
8xB 4xW 2xD 1xQ 16xB 8xW 4xD 2xQ 1xO
--------------------------------------------------------------------
+----------------------------+ +-----------------------------------+
x86 PAND PAND ANDPS ANDPD
PANDN PANDN ANDNPS ANDNPD
POR POR ORPS ORPD
PXOR PXOR XORPS XORPD
+----------------------------+ +-----------------------------------+
ia64 Standart
+----------------------------+ +-----------------------------------+
Alpha Standart
+----------------------------+ +-----------------------------------+
MIPS AND.OB AND.QH
OR.OB OR.QH
NOR.OB NOR.QH
XOR.OB XOR.QH
+----------------------------+ +-----------------------------------+
PPC VAND
VANDC
VNOR
VOR
VXOR
+----------------------------+ +-----------------------------------+
SPARC FOR
FNOR
FAND
FNAND
FXOR
FXNOR
FANDNOT1
FORNOT1
FORNOT2
---------------------------------------------------------------------------
Vector parallel shift
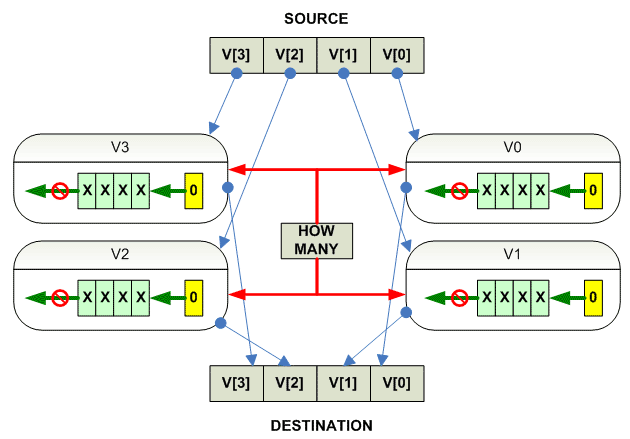
parallel
{
destination[i] = source[i] << count
}
|
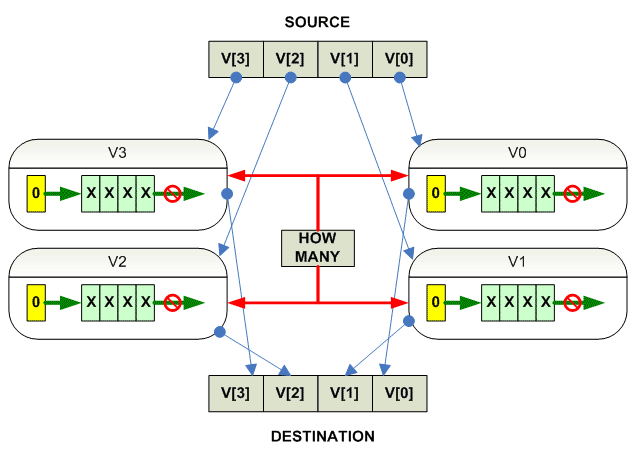
parallel
{
destination[i] = source[i] >> count
}
|
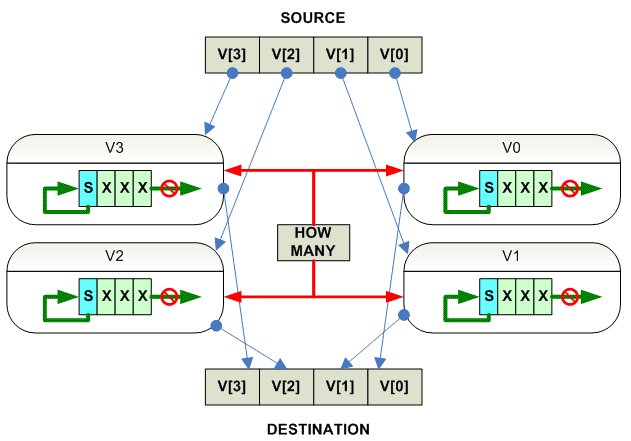
parallel
{
destination[i] = source[i] >>> count
}
|
---------------------------------------------------------------------------
VECTOR SHIFT (ALL)
--------------------------------------------------------------------
64 64 64 64 128 128 128 128 128
8xB 4xW 2xD 1xQ 16xB 8xW 4xD 2xQ 1xO
--------------------------------------------------------------------
x86 PSLLW PSLLD PSLLQ PSLLW PSLLD PSLLQ PSLLDQ
PSRLW PSRLD PSRLQ PSRLW PSRLD PSRLQ PSRLDQ
PSRAW PSRAD ? PSRAW PSRAD ? ?
--------------------------------------------------------------------
ia64 PSHL2 PSHL4 (SHL)
PSHR2 PSHR4 (SHR)
(.u) (.u) (.u)
--------------------------------------------------------------------
Alpha
--------------------------------------------------------------------
MIPS SLL.OB SLL.QH
SRL.OB SRL.QH
SRA.OB SRA.QH
--------------------------------------------------------------------
PPC VSLB VSLH VSLW VSLO VSL
VSRB VSRH VSRW VSRO VSR
VSRAB VSRAH VSRAW ? ?
--------------------------------------------------------------------
SPARC
---------------------------------------------------------------------------
Vector parallel multiply
Общий вид:
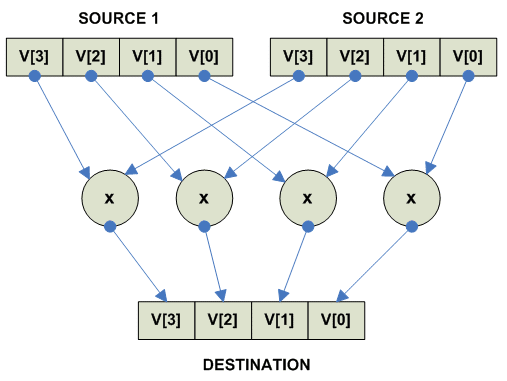
В реальности существуют несколько вариантов умножения:
для обычной арифметики:
- Multiply Low (он одинаковый для Signed и Unsigned)
- Multiply High Signed
- Multiply High Unsigned
для арифметики с насыщением:
- Multiply Low Saturated Signed
- Multiply Low Saturated Unsigned
Multiply Low:
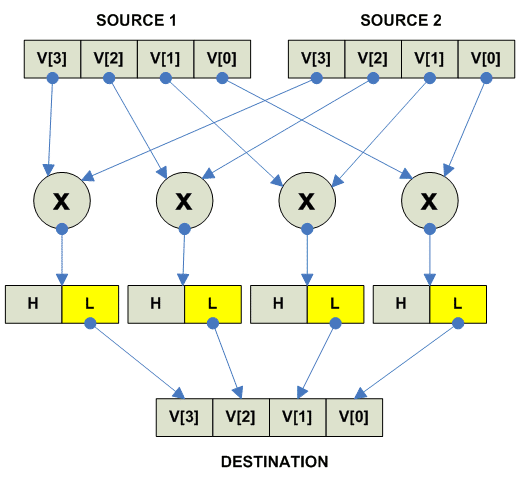
parallel
{
destination[i] = LO(source1[i] * source2[i])
}
|
Multiply High (помним что есть два варианта):
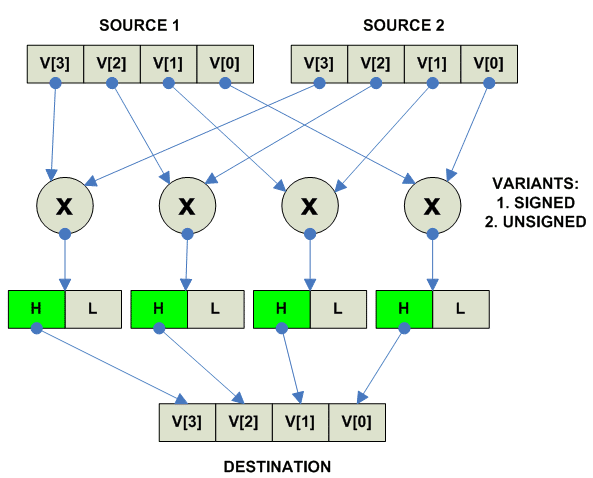
parallel
{ U
destination[i] = HI(source1[i] * source2[i])
}
parallel
{ S
destination[i] = HI(source1[i] * source2[i])
}
|
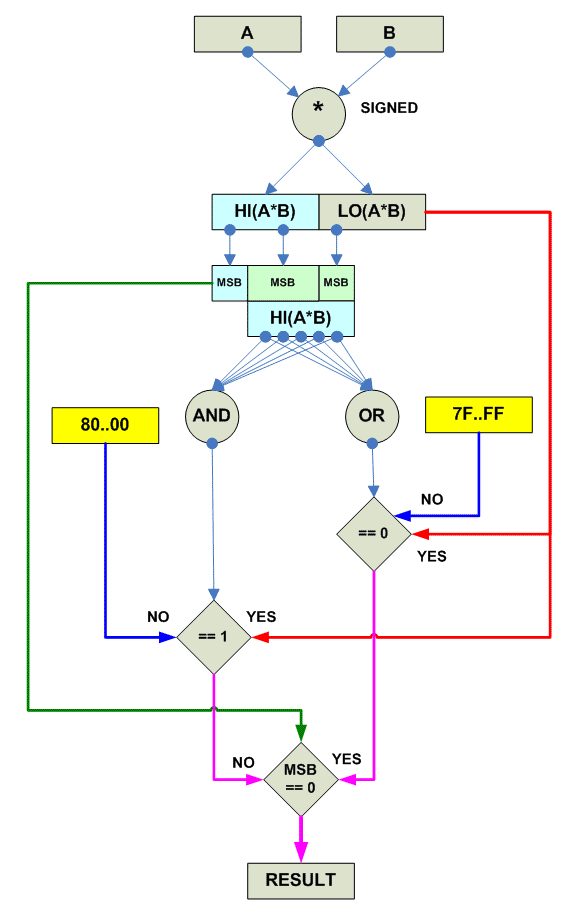
Saturated Multiply (есть Signed, есть Unsigned):
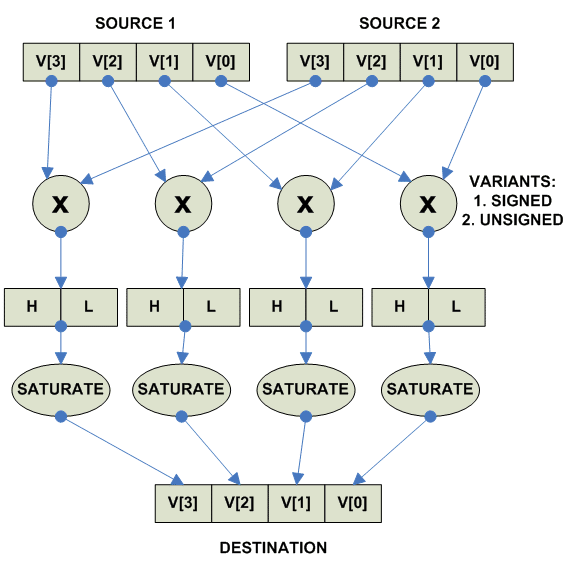
parallel
{ U
destination[i] = Unsigned_Saturate(source1[i] * source2[i])
}
parallel
{ S
destination[i] = Signed_Saturate(source1[i] * source2[i])
}
|
Варианты реализации (совсем не оптимизированные):
Saturated Multiply Unsigned:
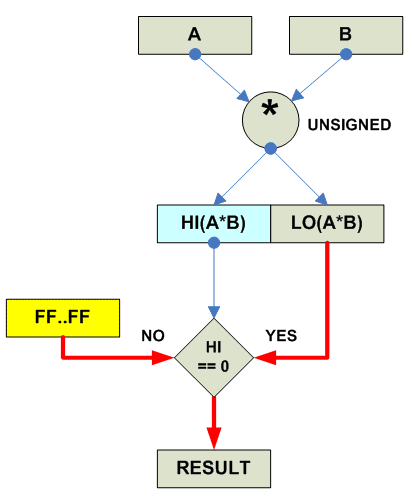
Saturated Multiply Signed:
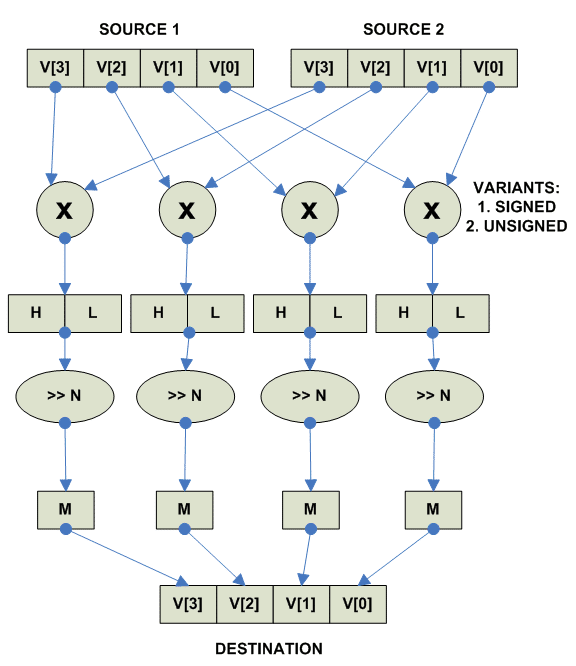
Следущий вариант более общий - умножение N*N => 2N, сдвиг на указанное
число битов (и как правило еще и saturation (на рисунке не показано)
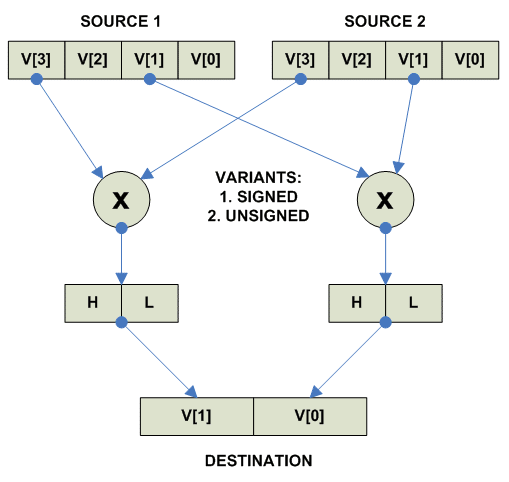
Еще существуют варианты когда в результате умножения получается вектор
большей разрядности:
Vector Multiply Left:
Vector Multiply Right:
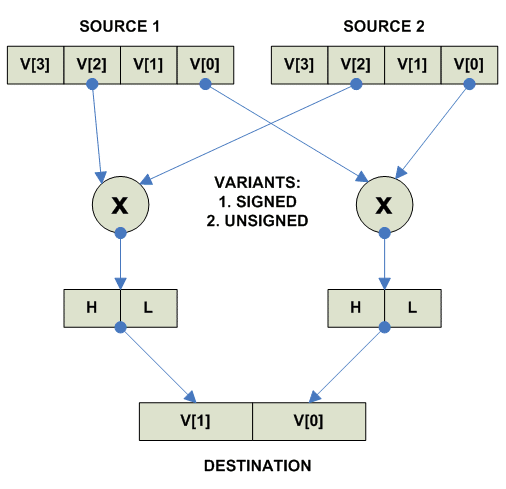
Эти формы могут быть как signed, так и unsigned
---------------------------------------------------------------------------
VECTOR MULTIPLY (ALL)
--------------------------------------------------------------------
64 64 64 64 128 128 128 128 128
8xB 4xW 2xD 1xQ 16xB 8xW 4xD 2xQ 1xO
--------------------------------------------------------------------
x86 PMULHW PMULHW
PMULLW PMULUDQ PMULLW PMULUDQ
--------------------------------------------------------------------
ia64 PMPY2
--------------------------------------------------------------------
Alpha
--------------------------------------------------------------------
MIPS MUL.OB MUL.QH
--------------------------------------------------------------------
PPC VMULESB VMULESH
VMULOSB VMULOSH
VMULEUB VMULEUH
VMULOUB VMULOUH
--------------------------------------------------------------------
SPARC +------------------------------+
FMUL8x16
FMUL8SUx16
FMULD8SUx16
FMULD8ULx16
---------------------------------------------------------------------------
Multiply and Add (Accumulate)
THIS SECTION IS UNDER CONSTRUCTION
Multiply and Add:
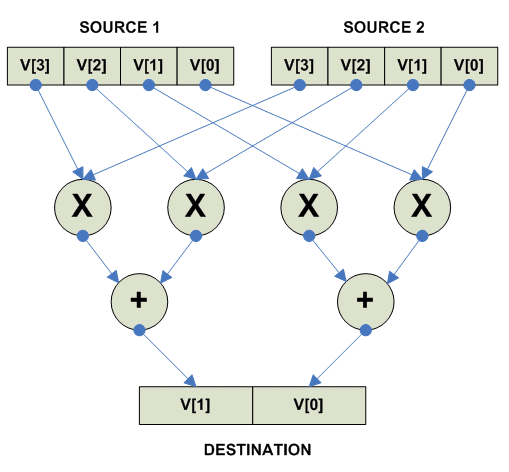
Multiply and Add Saturated
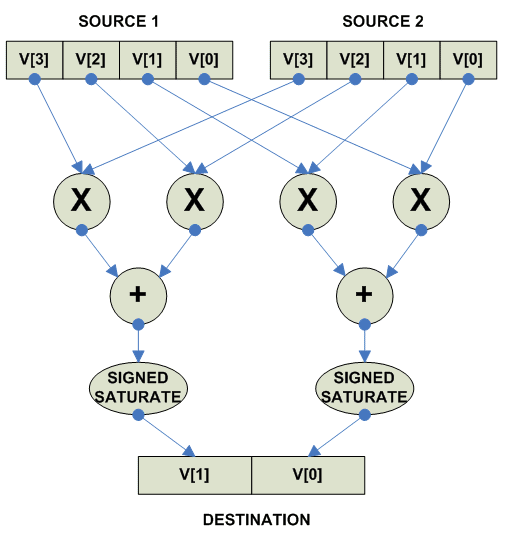
Обратите внимание, что у этой операции размер элемента target вектора
больше чем у source.
Операция использьзуется для получения dot product.
Соответсвенно востребована в codecs.
---------------------------------------------------------------------------
VECTOR MULTIPLY-ADD (ALL)
--------------------------------------------------------------------
64 64 64 64 128 128 128 128 128
8xB 4xW 2xD 1xQ 16xB 8xW 4xD 2xQ 1xO
--------------------------------------------------------------------
x86 PMADDWD PMADDWD
--------------------------------------------------------------------
ia64
--------------------------------------------------------------------
Alpha
--------------------------------------------------------------------
MIPS MULA.OB MULA.QH
--------------------------------------------------------------------
PPC VMSUMMMM VMSUMSHM
VMSUMUBM VMSUMSHS
VMSUMUHM
VMSUMUHS
--------------------------------------------------------------------
SPARC
---------------------------------------------------------------------------
Vector sum of absolute difference
THIS SECTION IS UNDER CONSTRUCTION
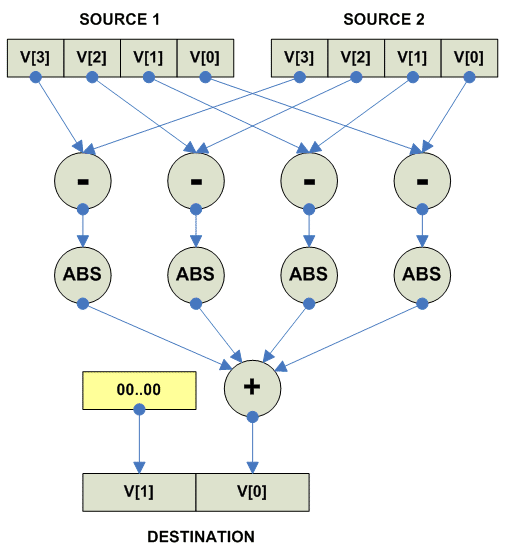
Обратите внимание, что у этой операции размер элемента target вектора
больше чем у source.
Операция часто используется в codecs.
---------------------------------------------------------------------------
VECTOR SUM OF ABSOLUTE DIFFERENCE
--------------------------------------------------------------------
64 64 64 64 128 128 128 128 128
8xB 4xW 2xD 1xQ 16xB 8xW 4xD 2xQ 1xO
--------------------------------------------------------------------
x86 PSADBW PSADBW
--------------------------------------------------------------------
ia64 PSAD1
--------------------------------------------------------------------
Alpha
--------------------------------------------------------------------
MIPS
--------------------------------------------------------------------
PPC
--------------------------------------------------------------------
SPARC
---------------------------------------------------------------------------
Vector Load
Vector load:
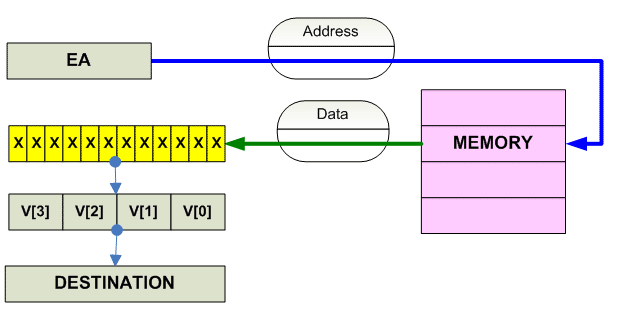
Scalar load:
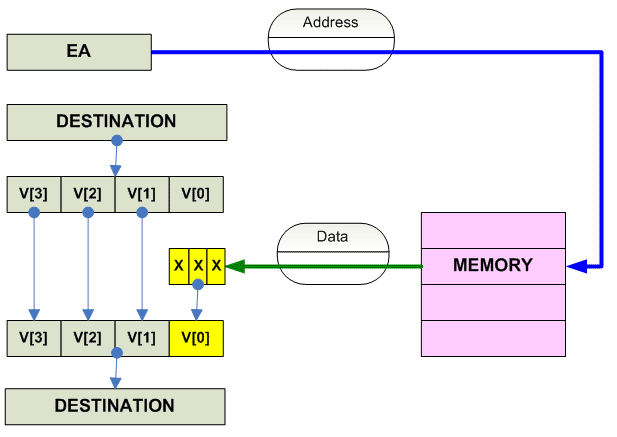
---------------------------------------------------------------------------
VECTOR LOAD
--------------------------------------------------------------------
64 64 64 64 128 128 128 128 128
8xB 4xW 2xD 1xQ 16xB 8xW 4xD 2xQ 1xO
--------------------------------------------------------------------
+----------------------------+ +-----------------------------------+
x86 MOVD (32) MOVDQA MOVDQU
MOVQ (64) MOVHPD (hi part)
MOVLPD (lo part)
+----------------------------+ +-----------------------------------+
ia64 Standart
+----------------------------+ +-----------------------------------+
Alpha Standart
+----------------------------+ +-----------------------------------+
MIPS Standart
(LDC1)
(LDXC1)
(LUXC1)
+----------------------------+ +-----------------------------------+
PPC LVX
LVEBX (element B)
LVEHW (element W)
LVEWX (element X)
+----------------------------+ +-----------------------------------+
SPARC Standart Standart
(LDDFA) (LDDA) (128-bit 2xFP)
---------------------------------------------------------------------------
Vector store
Vector store
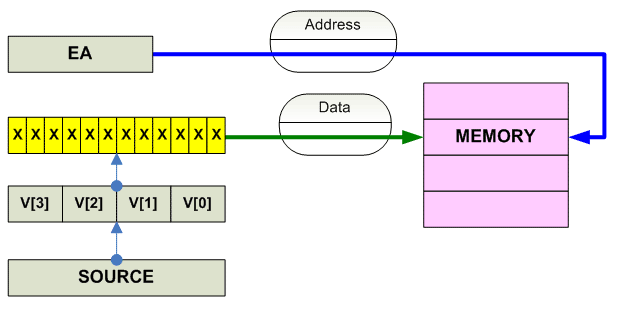
Scalar store
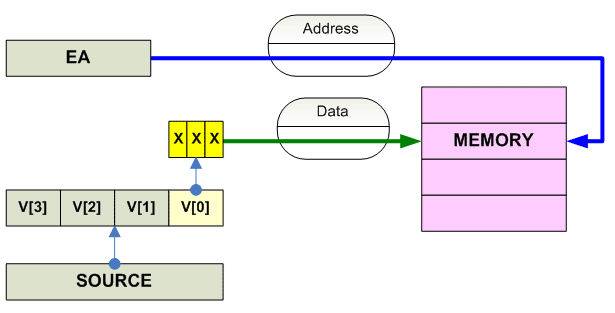
---------------------------------------------------------------------------
VECTOR STORE
--------------------------------------------------------------------
64 64 64 64 128 128 128 128 128
8xB 4xW 2xD 1xQ 16xB 8xW 4xD 2xQ 1xO
--------------------------------------------------------------------
+----------------------------+ +-----------------------------------+
x86 MOVD (32) MOVDQA MOVDQU
MOVQ (64) MOVHPD (hi part)
MOVLPD (lo part)
+----------------------------+ +-----------------------------------+
ia64 Standart
+----------------------------+ +-----------------------------------+
Alpha Standart
+----------------------------+ +-----------------------------------+
MIPS Standart
(SDC1)
(SDXC1)
(SUXC1)
+----------------------------+ +-----------------------------------+
PPC STVX
STVEBX (element B)
STVEHW (element H)
STVEWX (element W)
+----------------------------+ +-----------------------------------+
SPARC Standart
(STDFA)
---------------------------------------------------------------------------
Vector parallel compare
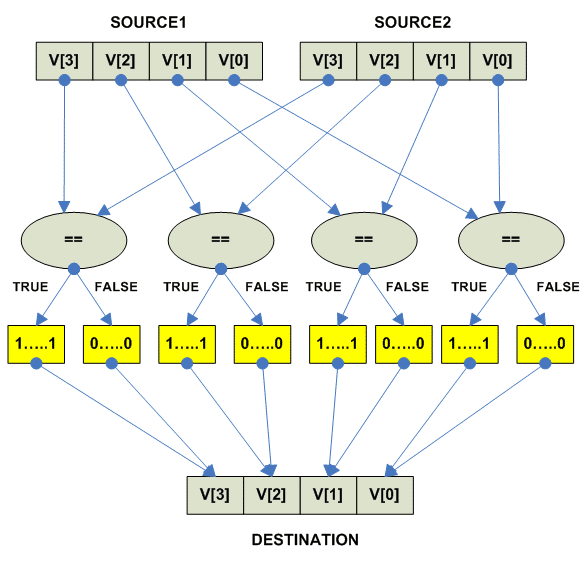
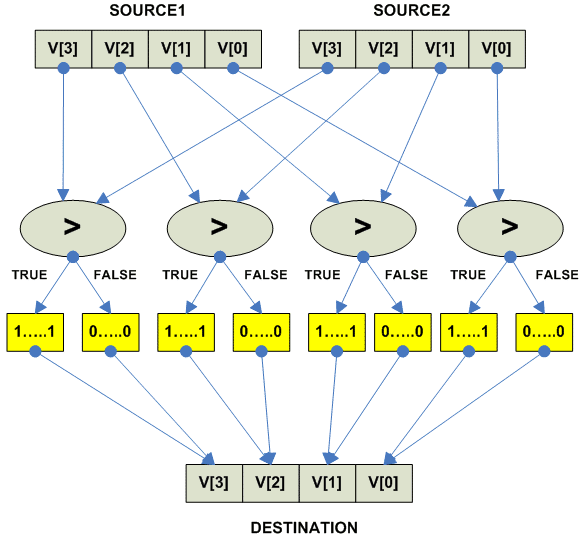
---------------------------------------------------------------------------
VECTOR PARALLEL COMPARE (ALL)
--------------------------------------------------------------------
64 64 64 64 128 128 128 128 128
8xB 4xW 2xD 1xQ 16xB 8xW 4xD 2xQ 1xO
--------------------------------------------------------------------
x86 PCMPEQB PCMPEQW PCMPEQD PCMPEQB PCMPEQW PCMPEQD
PCMPGTB PCMPGTW PCMPGTD PCMPGTB PCMPGTW PCMPGTD
--------------------------------------------------------------------
ia64 PCMP1 PCMP2 PCMP4
--------------------------------------------------------------------
Alpha
--------------------------------------------------------------------
MIPS C.EQ.OB C.EQ.QH
C.LE.OB C.LE.QH
C.GT.OB C.GT.QH
--------------------------------------------------------------------
PPC VCMPEQUB VCMPEQUH VCMPEQUW
VCMPGTSB VCMPGTSH VCMPGTSW
VCMPGTUB VCMPGTUH VCMPGTUW
--------------------------------------------------------------------
SPARC FCMPGT16 FCMPGT32
FCMPNE16 FCMPNE32
FCMPLE16 FCMPLE32
FCMPEQ16 FCMPEQ32
---------------------------------------------------------------------------
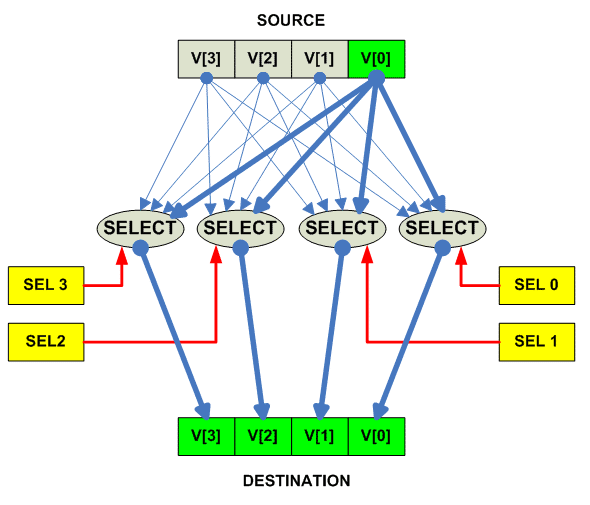
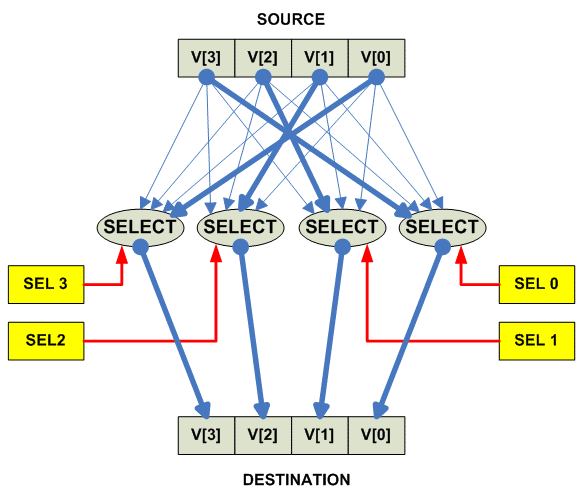
Shuffle vector
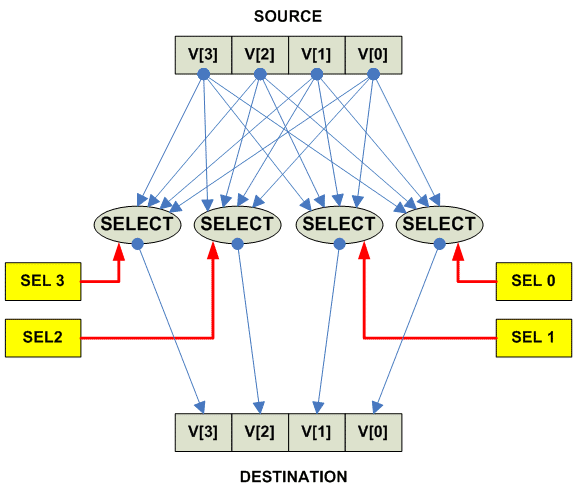
Наиболее частое использование Vector Shuffle - это распространение скаляра
по векторному регистру (broadcast).
Другой частый пример - это reverse - изменение порядка следования
на обратный:
---------------------------------------------------------------------------
VECTOR SHUFFLE
--------------------------------------------------------------------
64 64 64 64 128 128 128 128 128
8xB 4xW 2xD 1xQ 16xB 8xW 4xD 2xQ 1xO
--------------------------------------------------------------------
x86 PSHUFW PSHUFD SHUFPD
SHUFPS
--------------------------------------------------------------------
ia64 MIX1 MIX2 MIX4
MUX1 MUX2
--------------------------------------------------------------------
Alpha
--------------------------------------------------------------------
MIPS SHFL.PACH.OB
SHFL.PACK.OB
SHFL.MIXH.OB
SHFL.MIXL.OB
SHFL.PACH.QH
SHFL.PACK.QH
SHFL.MIXH.QH
SHFL.MIXL.QH
--------------------------------------------------------------------
PPC VMRGHB VMRGHH VMRGHW
--------------------------------------------------------------------
SPARC first BMASK
then BSHUFFLE
---------------------------------------------------------------------------
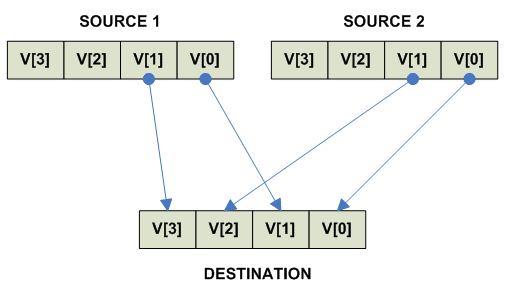
Vector pack/unpack
THIS SECTION IS UNDER CONSTRUCTION
Pack:
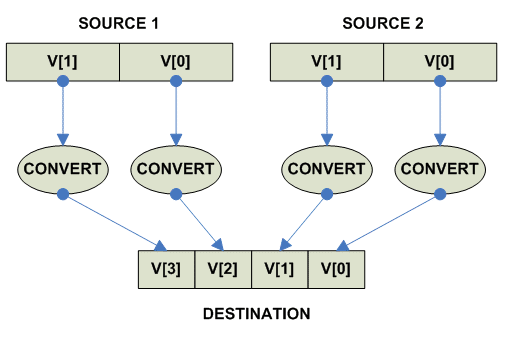
Unpack High:
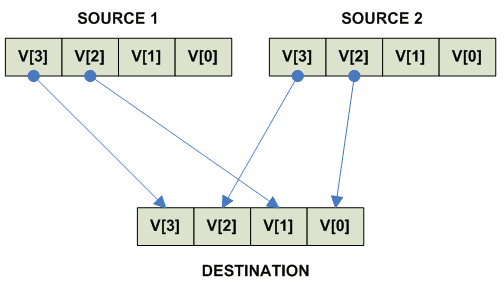
Unpack Low:
---------------------------------------------------------------------------
VECTOR PACK/UNPACK
--------------------------------------------------------------------
64 64 64 64 128 128 128 128 128
8xB 4xW 2xD 1xQ 16xB 8xW 4xD 2xQ 1xO
--------------------------------------------------------------------
x86 PACKSSWB PACKSSWB
PACKSSDW PACKSSDW
PACKUSWD PACKUSWD
PUNPCKHBW PUNPCKHBW
PUNPCKLBW PUNPCKLBW
PUNPCKHWD PUNPCKHWD
PUNPCKLWD PUNPCKLWD
PUNPCKHDQ PUNPCKHDQ
PUNPCKLDQ PUNPCKLDQ
--------------------------------------------------------------------
ia64 PACK2
PACK4
UNPACK1
UNPACK2
UNPACK4
--------------------------------------------------------------------
Alpha PKLB
PKWB
UNPCKBL
UNPCKBW
--------------------------------------------------------------------
MIPS
--------------------------------------------------------------------
PPC VPKSHSS
VPKSHUS
VPKSWSS
VPKSWUS
VPKUHUM
VPKUHUS
VPKUWUM
VPKUWUS
VUPKHPX
VUPKHSB
VUPKHSH
VUPKLPX
VUPKLSB
VUPKLSH
--------------------------------------------------------------------
SPARC FPACK16
FPACK32
FEXPAND?
---------------------------------------------------------------------------
Index Prev Next