70.1.2. ПРЕДСТАВЛЕНИЕ СИМВОЛОВ
ASCII
Однобайтовое Представление символов
ASCII
ASCII (American Standart Code for Information Interchange).
Американский стандартный код для обмена информаций.
описывает 7 бит
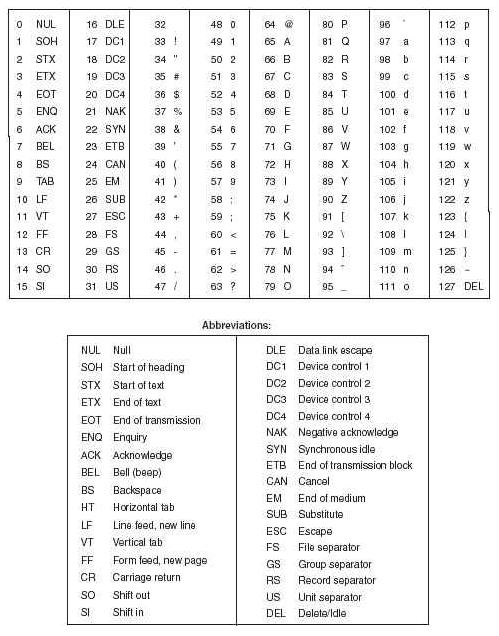
--+----------------------------------------------------------------
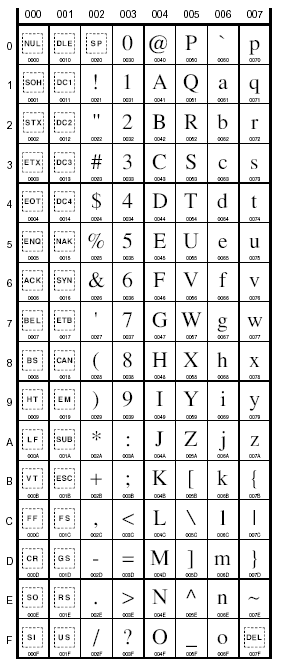
00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F
--+----------------------------------------------------------------
00 | NUL SOH STX ETX EOT ENQ ACK BEL BS HT LF VT FF CR SO SI
10 | DLE DC1 DC2 DC3 DC4 NAK SYN ETB CAN EM SUB ESC FS GS RS US
20 | SPC ! " # $ % & ' ( ) * + , - . /
30 | 0 1 2 3 4 5 6 7 8 9 : ; < = > ?
40 | @ A B C D E F G H I J K L M N O
50 | P Q R S T U V W X Y Z [ \ ] ^ _
60 | ` a b c d e f g h i j k l m n o
70 | p q r s t u v w x y z { | } ~ DEL
--+----------------------------------------------------------------
ASCII control codes:
----------------------------------
00 NUL (null)
01 SOH (start of heading)
02 STX (start of text)
03 ETX (end of text)
04 EOT (end of transmission)
05 ENQ (enquiry)
06 ACK (acknowledge)
07 BEL (bell)
08 BS (backspace)
09 TAB (horizontal tab)
0A LF (NL line feed, new line)
0B VT (vertical tab)
0C FF (NP form feed, new page)
0D CR (carriage return)
0E SO (shift out)
0F SI (shift in)
10 DLE (data link escape)
11 DC1 (device control 1)
12 DC2 (device control 2)
13 DC3 (device control 3)
14 DC4 (device control 4)
15 NAK (negative acknowledge)
16 SYN (synchronous idle)
17 ETB (end of trans. block)
18 CAN (cancel)
19 EM (end of medium)
1A SUB (substitute)
1B ESC (escape)
1C FS (file separator)
1D GS (group separator)
1E RS (record separator)
1F US (unit separator)
7F DEL (delete)
----------------------------------
+----------+
| | ASCII-Art
+----------+ |
| | \
| | --------\
| \ \
| ----------\ \
|------+ \ /
| \ \
\ | /
\ | /
------------------+
Я нарисовал носки, лишь используя ASCII.
Кодовые страницы
Если латинский алфавит отображается в ASCII, то для других
алфавитов- проблемы. Т.к. есть символы которые непредставимы в ASCII.
Поэтому делают расширение ASCII до 8-бит внося дополнительные символы.
Пример кодовой страницы Windows CP1250 (Western Europe)
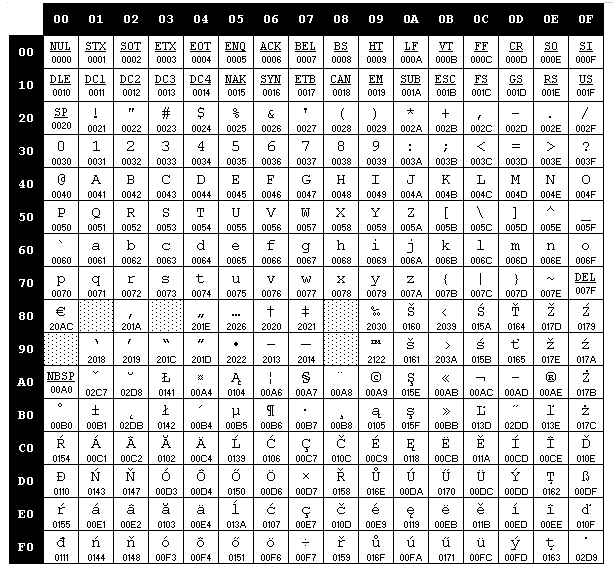
Т.к. много языков и стандартов, то много и codepages.
Основные кодовые страницы для русского языка:
DOS 866 Codepage DOS, OS/2, Windows ibm866
Windows 1251 Codepage Windows Windows-1251
KOI8-R UNIX koi8-r
ISO8859-5 OpenVMS iso-8859-5
Machintosh CP10007 Machintosh x-mac-cyrillic
UNICODE * *
Пример текстa:
-------------------------------------------------------------------------------
Привет мир
-------------------------------------------------------------------------------
CP Windows 1251:
-------------------------------------------------------------------------------
00000000: cf f0 e8 e2 e5 f2 20 ec e8 f0 [Привет мир ]
-------------------------------------------------------------------------------
CP DOS 866:
-------------------------------------------------------------------------------
00000000: 8f e0 a8 a2 a5 e2 20 ac a8 e0 [_аЁў_в ¬Ёа ]
[Привет мир ]
-------------------------------------------------------------------------------
KOI-8-R очень специфическая кодировка. Русские буквы в ней расположены так что
бы соответствовать англиским фонетическим аналогам.
Если убрать старший бит из байта - то KOI-8-R превратится в трудом но читаемый
транслит.
Пример:
KOI-8-R: "Русский Текст"
ACSII: "rUSSKIJ tEKST"
Windows CP1251 (Cyrilic)
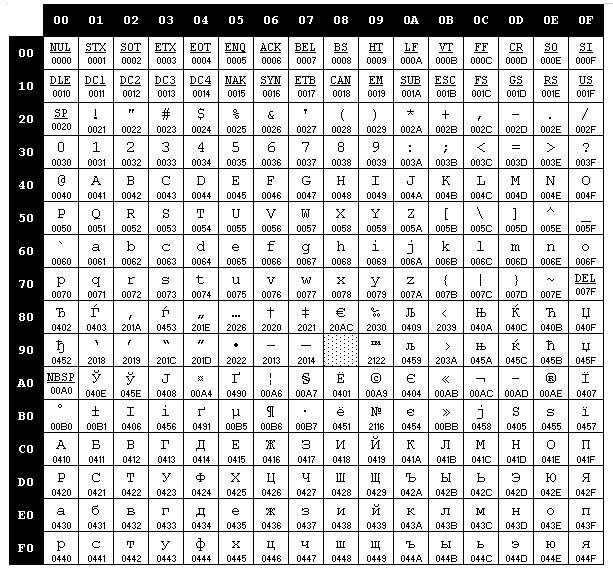
DOS CP866 (Cyrilic)
ISO8859-5 (Cyrilic)
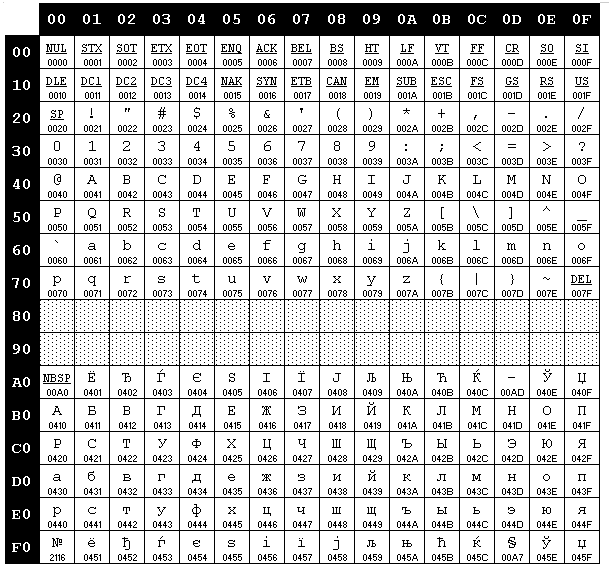
KOI-8-R (Cyrilic RUS)

Machintosh CP10007 (Machintosh Cyrilic)

MIC (Болгарская кодировка)

Multibyte
Все это конечно хорошо, но существуют языки которым мало 128 символов
(это азиатская группа - китайский, японский, корейский итд).
Они используют Multibyte - т.е. символ представляется не одним байтом
а несколькими (причем количество байтов зависит от самого символа).
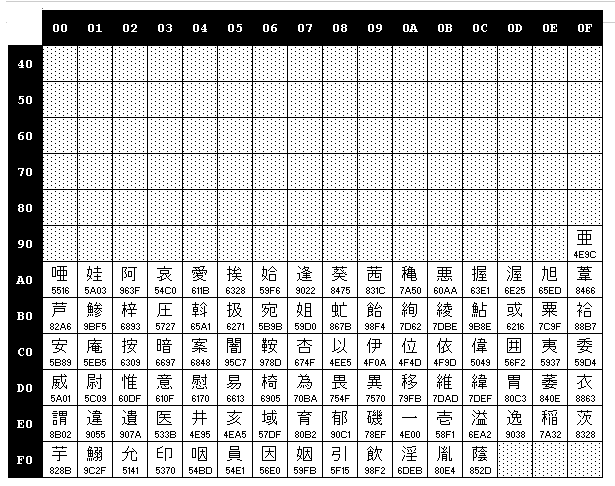
Пример главной таблицы multibyte кодировки 932 (Japanise):
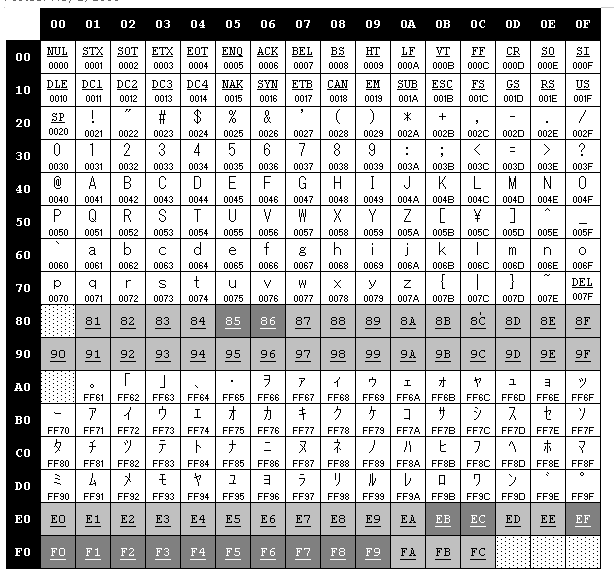
Пример таблицы кодировки 932 (если первый байт равен 88h):
EBCDIC
EBCDIC (Extended Binary-Coded Decimal Interchange code)
используется в IBM's mainframes.
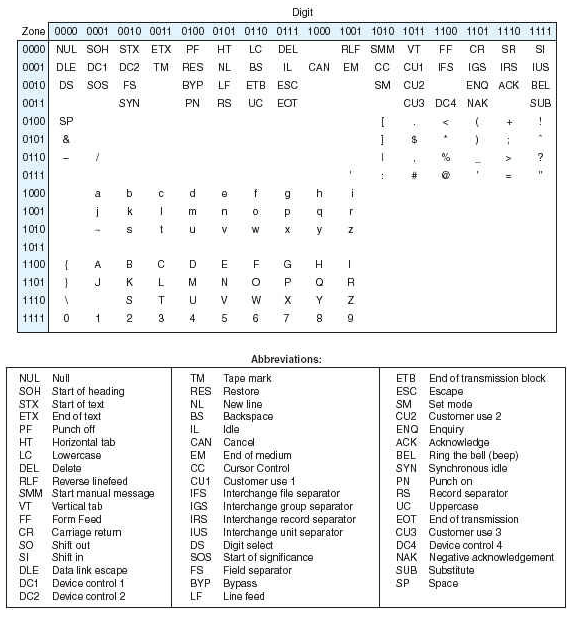
Такая чудовищная таблица потому что основа ввода в т врмена это перфокарты.
---------------------------------------------------------------------------------
00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F
---------------------------------------------------------------------------------
00 NULL PF HT LC DEL
10 RES NL BS IL
20 BYP LF EOB PRE SM
30 PN RS UC EOT
40 SP C$ . < ( + |
50 & ! $ * ) ; ^
60 _ / , % - > ?
70 : # @ ' = "
80 a b c d e f g h i
90 j k l m n o p q r
A0 s t u v w x y z
B0
C0 A B C D E F G H I
D0 J K L M N O P Q R
E0 S T U V W X Y Z
F0 0 1 2 3 4 5 6 7 8 9
---------------------------------------------------------------------------------

NULL
PF Perforator off
HT Horisontal tabulation
LC Lowercase char
DEL delete
RES restore
NL new line
BS backspace
IL illegal
BYP bypass
LF line feed
EOB end of block
PRE prefix
SM set mode
PN perforator on
RS Read stop
UC uppercase char
EOT end of transfer
SP space
C$ cent (1/100 of $)
Кстати у EBCDIC тоже есть кодовые страницы.
Текстовые файлы
К сожалению кроме кодовых страниц есть и другие заморочки:
Рассмотрим текстовый файл:
-------------------------
Hello
world
-------------------------
CP/M и унаследованные (например MSX-DOS)
разделитель строк - последовательность CR LF
текстовый файл должен кончаться символом EOF (26)
--------------------------
00000000: 48 65 6c 6c 6f 0d 0a 77 6f 72 64 1A .. .. .. [Hello..world. ]
--------------------------
DOS/Windows:
разделитель строк - последовательность CR LF
--------------------------
00000000: 48 65 6c 6c 6f 0d 0a 77 6f 72 64 .. .. .. .. [Hello..world ]
--------------------------
UNIX:
разделитель строк - LF
--------------------------
00000000: 48 65 6c 6c 6f 0a 77 6f 72 64 .. .. .. .. .. [Hello.world ]
--------------------------
Machintosh:
разделитель строк - CR
--------------------------
00000000: 48 65 6c 6c 6f 0d 77 6f 72 64 .. .. .. .. .. [Hello.world ]
--------------------------
UNICODE
Честно говоря тут тоже имеется Endian.
ASCII однозначно мапируется по принципу:
0000-1FFF Alphabets (Latin,Cirillic..)
2000-2FFF Symbols (Mathematical...)
3000-3FFF Chinese,Japanese,Korean phonetic symbols
4000-DFFF Chinese,Japanese,Korean symbols
E000-EFFF Reserved
F000-FFFF User defined
Более детальное описание:
----------------------------------------------------------
Базовый латинский алфавит (0000-007F)
Дополнительные символы Latin-1 (0080-00FF)
Расширенный латинский алфавит-A (0100-017F)
Расширенный латинский алфавит-B (0180-024F)
Международный фонетический алфавит (IPA)(0250-02AF)
Пробельные символы (02B0-02FF)
диакритические символы (0300-036F)
Греческий и коптский алфавиты (0370-03FF)
Кириллица (0400-04FF)
Дополнительные символы кириллицы (0500-052F)
Армянский алфавит (0530-058F)
Еврейский алфавит (0590-05FF)
Арабский алфавит (0600-06FF)
Сирийский алфавит (0700-074F)
Доп символы арабского алфавита (0750-077F)
Thaana (0780-07BF)
Индийские письменности:
Деванагари (0900-097F)
Бенгали (0980-09FF)
Gurmukhi (0A00-0A7F)
Gujarati (0A80-0AFF)
Oriya (0B00-0B7F)
Tamil (0B80-0BFF)
Telugu (0C00-0C7F)
Kannada (0C80-0CFF)
Malayalam (0D00-0D7F)
Sinhala (0D80-0DFF)
Тайский алфавит (0E00-0E7F)
Лаосская письменность (0E80-0EFF)
Тибетская письменность (0F00-0FFF)
Бирманский алфавит (1000-109F)
Грузинский алфавит (10A0-10FF)
Отдельные буквы (Jamo) хангыль (1100-11FF)
Амхарский язык (1200-137F)
Ethiopic Supplement (1380-139F)
Язык чероки (13A0-13FF)
Unified Canadian Aboriginal Syllabics (1400-167F)
Ogham (1680-169F)
Рунный алфавит (16A0-16FF)
Филиппинские письменности:
Tagalog (1700-171F)
Hanunoo (1720-173F)
Buhid (1740-175F)
Tagbanwa (1760-177F)
Кхмерский алфавит (1780-17FF)
Монгольский алфавит (1800-18AF)
Limbu (1900-194F)
Tai Le (1950-197F)
New Tai Lue (1980-19DF)
Khmer Symbols (19E0-19FF)
Buginese (1A00-1A1F)
Фонетические расширения (1D00-1D7F)
Дополнительные фонетичестие расширения (1D80-1DBF)
Дополнительные диакритические знаки (1DC0-1DFF)
Latin Extended Additional (1E00-1EFF)
Расширенный греческий алфавит (1F00-1FFF)
Символы:
Пунктуация (2000-206F)
Надстрочные и подстрочные знаки (2070-209F)
Символы валют (20A0-20CF)
Combining Diacritical Marks for Symbols (20D0-20FF)
Letterlike Symbols (2100-214F)
Number Forms (2150-218F)
Стрелки (2190-21FF)
Математические операторы (2200-22FF)
Прочие технические символы (2300-23FF)
Control Pictures (2400-243F)
Optical Character Recognition (2440-245F)
Enclosed Alphanumerics (2460-24FF)
Символы для рисования рамок (2500-257F)
Block Elements (2580-259F)
Геометрические фигуры (25A0-25FF)
Прочие символы (2600-26FF)
Dingbats (2700-27BF)
Miscellaneous Mathematical Symbols-A (27C0-27EF)
Supplemental Arrows-A (27F0-27FF)
Азбука Брайля (2800-28FF)
Supplemental Arrows-B (2900-297F)
Miscellaneous Mathematical Symbols-B (2980-29FF)
Supplemental Mathematical Operators (2A00-2AFF)
Miscellaneous Symbols and Arrows (2B00-2BFF)
Глаголица (2C00-2C5F)
Коптский алфавит (2C80-2CFF)
Georgian Supplement (2D00-2D2F)
Tifinagh (2D30-2D7F)
Ethiopic Extended (2D80-2DDF)
Supplemental Punctuation (2E00-2E7F)
CJK Radicals Supplement (2E80-2EFF)
Kangxi Radicals (2F00-2FDF)
Ideographic Description Characters (2FF0-2FFF)
CJK Symbols and Punctuation (3000-303F)
Хирагана (3040-309F)
Катакана (30A0-30FF)
Чжуинь (Бопомофо) (3100-312F)
Хангыль Compatibility Jamo (3130-318F)
Kanbun (3190-319F)
Расширение Бопомофо (31A0-31BF)
CJK Strokes (31C0-31EF)
Katakana Phonetic Extensions (31F0-31FF)
Enclosed CJK Letters and Months (3200-32FF)
CJK Compatibility (3300-33FF)
CJK Unified Ideographs Extension A (3400-4DBF)
Yijing Hexagram Symbols (4DC0-4DFF)
CJK Unified Ideographs (4E00-9FFF)
Yi Syllables (A000-A48F)
Yi Radicals (A490-A4CF)
Modifier Tone Letters (A700-A71F)
Syloti Nagri (A800-A82F)
Слоги хангыль (AC00-D7AF)
Верхняя часть суррогатных пар (D800-DB7F)
Верхняя часть суррогатных пар (DB80-DBFF)
Нижняя часть суррогатных пар (DC00-DFFF)
Область для частного использования (E000-F8FF)
CJK Compatibility Ideographs (F900-FAFF)
Alphabetic Presentation Forms (FB00-FB4F)
Arabic Presentation Forms-A (FB50-FDFF)
Variation Selectors (FE00-FE0F)
Vertical Forms (FE10-FE1F)
Combining Half Marks (FE20-FE2F)
CJK Compatibility Forms (FE30-FE4F)
Small Form Variants (FE50-FE6F)
Arabic Presentation Forms-B (FE70-FEFF)
Halfwidth and Fullwidth Forms (FF00-FFEF)
Специальные символы (FFF0-FFFF)
----------------------------------------------------------
Unicode (0000-007F, Latin)
Unicode (0080-00FF, Latin-1)
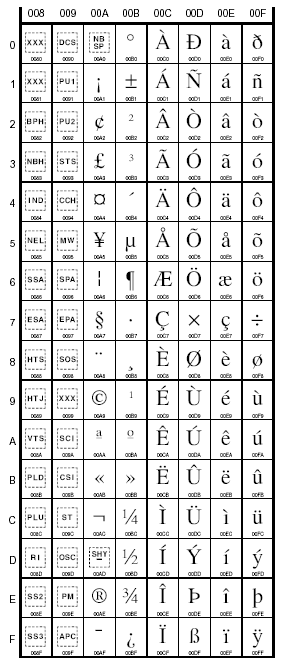
Unicode (0400-04FF, Cyrilic)

Все равно иероглифы все не уложили, поэтому приходится пользоватся кодовыми
страницами.
Текстовые файлы в UNICODE
Рассмотрим текстовый файл:
-------------------------
Hello
world
-------------------------
UNICODE текстовый файл всегда начинается с сигнатуры feffh - которая позволяет
определить endian этого файла.
Litle-endian Unicode:
--------------------------
00000000: ff fe 48 00 65 00 6c 00 6c 00 6f 00 0d 00 0a 00 [яюH e l l o . . ]
00000010: 77 00 6f 00 72 00 64 00 [w o r d ]
--------------------------
Big-endian Unicode
--------------------------
00000000: fe ff 00 48 00 65 00 6c 00 6c 00 6f 00 0d 00 0a [юя H e l l o . .]
00000010: 00 77 00 6f 00 72 00 64 [ w o r d ]
--------------------------
UTF-8
Для лучшей совместимости был придуман UTF-8 (Unicode Transformation Format).
Основная идея - ASCII символы (00-7F) идут без изменений. Если надо записывать
уже другие символы то они записываются в виде:
11xxxxxx первый байт
10xxxxxx остальные байты
Соответственно символы записываются как:
0000-007F 0xxxxxxx
0080-07FF 110xxxxx 10xxxxxx
0800-FFFF 1110xxxx 10xxxxxx 10xxxxxx
Системные вызовы Linux понимают UTF-8 формат имен.
А Windows работает с UTF-16LE unicode.
Соответсвенно документы начинаются с:
UTF-8 EF BB BF
UTF-16BE FE FF
UTF-16LE FF FE
UTF-32BE 00 00 FE FF
UTF-32LE FF FE 00 00
ASCII text:
-------------------------
Hello
world
-------------------------
UTF-8:
-------------------------
00000000: ef bb bf 48 65 6c 6c 6f 0d 0a 77 6f 72 6c 64 [п>їHello..world ]
-------------------------
Русский текст:
-------------------------------------------------------------------------------
Привет мир
-------------------------------------------------------------------------------
UTF-8:
-------------------------------------------------------------------------------
00000000: ef bb bf d0 9f d1 80 d0 b8 d0 b2 d0 b5 d1 82 20 [п>їР_С_РёР_РчС' ]
00000010: d0 bc d0 b8 d1 80 [Р_РёС_ ]
-------------------------------------------------------------------------------
Ужасы
Если бы дело ограничивалась только файлами, но к сожалению это проникает везде.
Когда у нас в Windows программа начинает выдавать в меню "зюки" - то у нас
системный шрифт для другой кодовой таблицы.
А самое ужасное это то что эти вещи действуют на имена файлов и в архивах и
на файловых системах (везде где у нас используются однобайтовые представления
для символов).
Index Prev Next